зеркало из
https://github.com/ssciwr/AMMICO.git
synced 2025-10-29 13:06:04 +02:00
Merge 4a18b1b5a99cb7d6cb99171fb461189d7dd71758 into 3f9e855aebddf6eddaa81de1cd883bc5bcf5d3bc
Этот коммит содержится в:
Коммит
4e86602184
2
.github/workflows/ci.yml
поставляемый
2
.github/workflows/ci.yml
поставляемый
@ -31,7 +31,7 @@ jobs:
|
||||
- name: Run pytest
|
||||
run: |
|
||||
cd ammico
|
||||
python -m pytest -svv -m "not gcv" --cov=. --cov-report=xml
|
||||
python -m pytest -svv -m "not gcv and not long" --cov=. --cov-report=xml
|
||||
- name: Upload coverage
|
||||
if: matrix.os == 'ubuntu-latest' && matrix.python-version == '3.11'
|
||||
uses: codecov/codecov-action@v3
|
||||
|
||||
4
FAQ.md
4
FAQ.md
@ -62,6 +62,10 @@ Be careful, it requires around 7 GB of disk space.
|
||||
|
||||
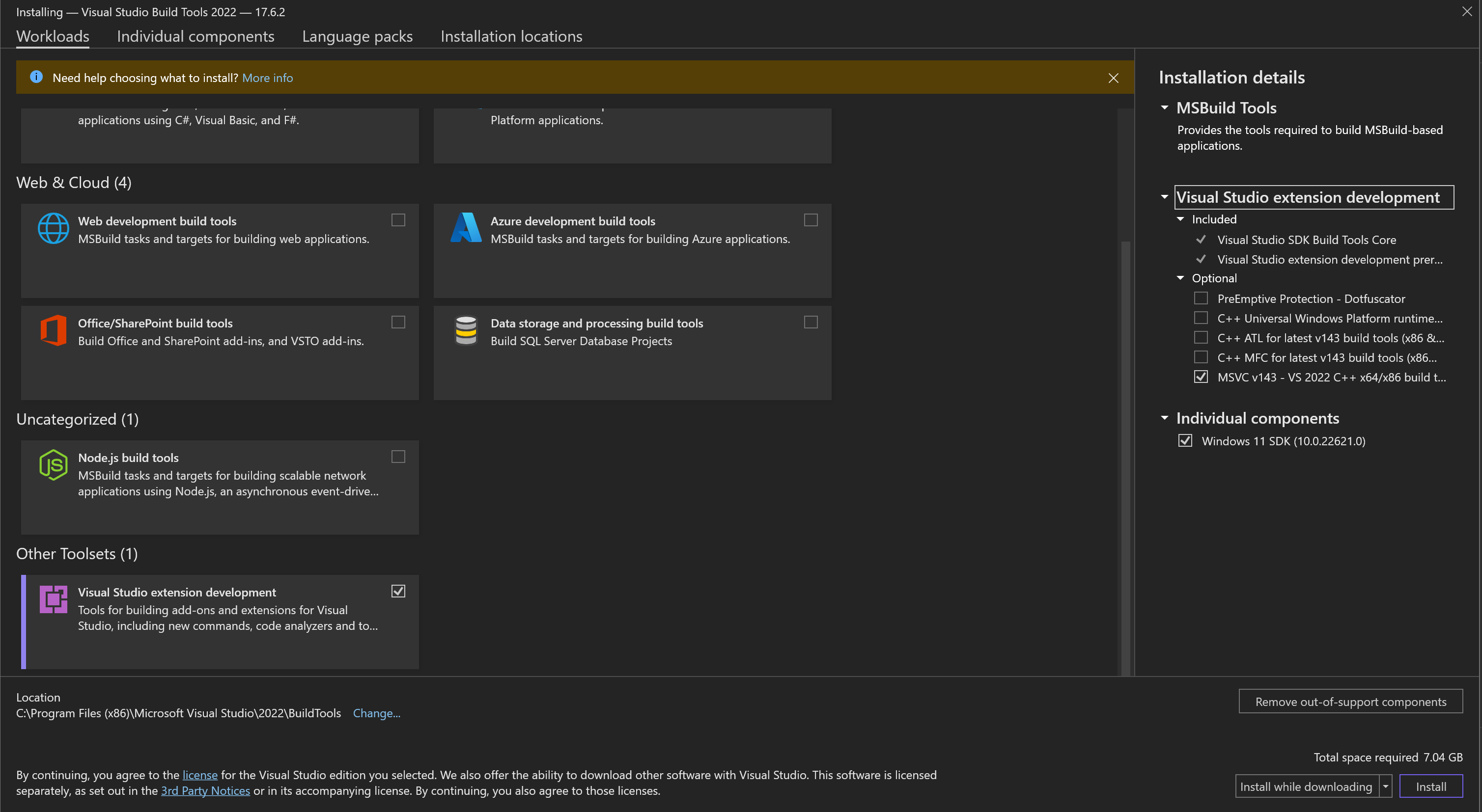
|
||||
|
||||
### Version clashes between tensorflow and numpy
|
||||
|
||||
Due to the `faces` module, the tensorflow version is currently fixed to at most `2.14.0`. This requires that `numpy` is restricted to `numpy==1.23.5`. If you experience issues with compatibility between tensorflow and numpy, you can try fixing the numpy version to this version.
|
||||
|
||||
## What happens to the images that are sent to google Cloud Vision?
|
||||
|
||||
You have to accept the privacy statement of ammico to run this type of analyis.
|
||||
|
||||
@ -22,7 +22,10 @@ Use pre-processed image files such as social media posts with comments and proce
|
||||
1. Content extraction from the images
|
||||
1. Textual summary of the image content ("image caption") that can be analyzed further using the above tools
|
||||
1. Feature extraction from the images: User inputs query and images are matched to that query (both text and image query)
|
||||
1. Question answering
|
||||
1. Question answering about image content
|
||||
1. Content extractioni from the videos
|
||||
1. Textual summary of the video content that can be analyzed further
|
||||
1. Question answering about video content
|
||||
1. Performing person and face recognition in images
|
||||
1. Face mask detection
|
||||
1. Probabilistic detection of age, gender and race
|
||||
@ -69,7 +72,8 @@ The [Hugging Face transformers library](https://huggingface.co/) is used to perf
|
||||
|
||||
### Content extraction
|
||||
|
||||
The image content ("caption") is extracted using the [LAVIS](https://github.com/salesforce/LAVIS) library. This library enables vision intelligence extraction using several state-of-the-art models such as BLIP and BLIP2, depending on the task and user selection. Further, it allows feature extraction from the images, where users can input textual and image queries, and the images in the database are matched to that query (multimodal search). Another option is question answering, where the user inputs a text question and the library finds the images that match the query.
|
||||
The image and video content ("caption") is now extracted using the Qwen2.5-VL
|
||||
model. Qwen2.5-VL is a multimodal large language model capable of understanding and generating content from both images and videos. With its help, AMMMICO supports tasks such as image/video summarization and image/video visual question answering, where the model answers users' questions about the context of a media file.
|
||||
|
||||
### Emotion recognition
|
||||
|
||||
|
||||
82
TESTING_WITH_MOCKS.md
Обычный файл
82
TESTING_WITH_MOCKS.md
Обычный файл
@ -0,0 +1,82 @@
|
||||
# Testing with Mock Models
|
||||
|
||||
This document explains how to use the mock model fixture to write fast unit tests that don't require loading the actual model.
|
||||
|
||||
## Mock Model Fixture
|
||||
|
||||
A `mock_model` fixture has been added to `conftest.py` that creates a lightweight mock of the `MultimodalSummaryModel` class. This fixture:
|
||||
|
||||
- **Does not load any actual models** (super fast)
|
||||
- **Mocks all necessary methods** (processor, tokenizer, model.generate, etc.)
|
||||
- **Returns realistic tensor shapes** (so the code doesn't crash)
|
||||
- **Can be used for fast unit tests** that don't need actual model inference
|
||||
|
||||
## Usage
|
||||
|
||||
Simply use `mock_model` instead of `model` in your test fixtures:
|
||||
|
||||
```python
|
||||
def test_my_feature(mock_model):
|
||||
detector = ImageSummaryDetector(summary_model=mock_model, subdict={})
|
||||
# Your test code here
|
||||
pass
|
||||
```
|
||||
|
||||
## When to Use Mock vs Real Model
|
||||
|
||||
### Use `mock_model` when:
|
||||
- Testing utility functions (like `_clean_list_of_questions`)
|
||||
- Testing input validation logic
|
||||
- Testing data processing methods
|
||||
- Testing class initialization
|
||||
- **Any test that doesn't need actual model inference**
|
||||
|
||||
### Use `model` (real model) when:
|
||||
- Testing end-to-end functionality
|
||||
- Testing actual caption generation quality
|
||||
- Testing actual question answering
|
||||
- Integration tests that verify model behavior
|
||||
- **Any test marked with `@pytest.mark.long`**
|
||||
|
||||
## Example Tests Added
|
||||
|
||||
The following new tests use the mock model:
|
||||
|
||||
1. `test_image_summary_detector_init_mock` - Tests initialization
|
||||
2. `test_load_pil_if_needed_string` - Tests image loading
|
||||
3. `test_is_sequence_but_not_str` - Tests utility methods
|
||||
4. `test_validate_analysis_type` - Tests validation logic
|
||||
|
||||
All of these run quickly without loading the model.
|
||||
|
||||
## Running Tests
|
||||
|
||||
### Run only fast tests (with mocks):
|
||||
```bash
|
||||
pytest ammico/test/test_image_summary.py -v
|
||||
```
|
||||
|
||||
### Run only long tests (with real model):
|
||||
```bash
|
||||
pytest ammico/test/test_image_summary.py -m long -v
|
||||
```
|
||||
|
||||
### Run all tests:
|
||||
```bash
|
||||
pytest ammico/test/test_image_summary.py -v
|
||||
```
|
||||
|
||||
## Customizing the Mock
|
||||
|
||||
If you need to customize the mock's behavior for specific tests, you can override its methods:
|
||||
|
||||
```python
|
||||
def test_custom_behavior(mock_model):
|
||||
# Customize the mock's return value
|
||||
mock_model.tokenizer.batch_decode.return_value = ["custom", "output"]
|
||||
|
||||
detector = ImageSummaryDetector(summary_model=mock_model, subdict={})
|
||||
# Test with custom behavior
|
||||
pass
|
||||
```
|
||||
|
||||
@ -1,6 +1,8 @@
|
||||
from ammico.display import AnalysisExplorer
|
||||
from ammico.faces import EmotionDetector, ethical_disclosure
|
||||
from ammico.model import MultimodalSummaryModel
|
||||
from ammico.text import TextDetector, TextAnalyzer, privacy_disclosure
|
||||
from ammico.image_summary import ImageSummaryDetector
|
||||
from ammico.utils import find_files, get_dataframe
|
||||
|
||||
# Export the version defined in project metadata
|
||||
@ -14,8 +16,10 @@ except ImportError:
|
||||
__all__ = [
|
||||
"AnalysisExplorer",
|
||||
"EmotionDetector",
|
||||
"MultimodalSummaryModel",
|
||||
"TextDetector",
|
||||
"TextAnalyzer",
|
||||
"ImageSummaryDetector",
|
||||
"find_files",
|
||||
"get_dataframe",
|
||||
"ethical_disclosure",
|
||||
|
||||
@ -1,10 +1,14 @@
|
||||
import ammico.faces as faces
|
||||
import ammico.text as text
|
||||
import ammico.colors as colors
|
||||
import ammico.image_summary as image_summary
|
||||
from ammico.model import MultimodalSummaryModel
|
||||
import pandas as pd
|
||||
from dash import html, Input, Output, dcc, State, Dash
|
||||
from PIL import Image
|
||||
import dash_bootstrap_components as dbc
|
||||
import warnings
|
||||
from typing import Dict, Any, List, Optional
|
||||
|
||||
|
||||
COLOR_SCHEMES = [
|
||||
@ -94,7 +98,8 @@ class AnalysisExplorer:
|
||||
State("left_select_id", "options"),
|
||||
State("left_select_id", "value"),
|
||||
State("Dropdown_select_Detector", "value"),
|
||||
State("setting_Text_analyse_text", "value"),
|
||||
State("Dropdown_analysis_type", "value"),
|
||||
State("textarea_questions", "value"),
|
||||
State("setting_privacy_env_var", "value"),
|
||||
State("setting_Emotion_emotion_threshold", "value"),
|
||||
State("setting_Emotion_race_threshold", "value"),
|
||||
@ -108,9 +113,15 @@ class AnalysisExplorer:
|
||||
Output("settings_TextDetector", "style"),
|
||||
Output("settings_EmotionDetector", "style"),
|
||||
Output("settings_ColorDetector", "style"),
|
||||
Output("settings_VQA", "style"),
|
||||
Input("Dropdown_select_Detector", "value"),
|
||||
)(self._update_detector_setting)
|
||||
|
||||
self.app.callback(
|
||||
Output("textarea_questions", "style"),
|
||||
Input("Dropdown_analysis_type", "value"),
|
||||
)(self._show_questions_textarea_on_demand)
|
||||
|
||||
# I split the different sections into subfunctions for better clarity
|
||||
def _top_file_explorer(self, mydict: dict) -> html.Div:
|
||||
"""Initialize the file explorer dropdown for selecting the file to be analyzed.
|
||||
@ -157,14 +168,6 @@ class AnalysisExplorer:
|
||||
id="settings_TextDetector",
|
||||
style={"display": "none"},
|
||||
children=[
|
||||
dbc.Row(
|
||||
dcc.Checklist(
|
||||
["Analyse text"],
|
||||
["Analyse text"],
|
||||
id="setting_Text_analyse_text",
|
||||
style={"margin-bottom": "10px"},
|
||||
),
|
||||
),
|
||||
# row 1
|
||||
dbc.Row(
|
||||
dbc.Col(
|
||||
@ -272,8 +275,69 @@ class AnalysisExplorer:
|
||||
)
|
||||
],
|
||||
),
|
||||
# start VQA settings
|
||||
html.Div(
|
||||
id="settings_VQA",
|
||||
style={"display": "none"},
|
||||
children=[
|
||||
dbc.Card(
|
||||
[
|
||||
dbc.CardBody(
|
||||
[
|
||||
dbc.Row(
|
||||
dbc.Col(
|
||||
dcc.Dropdown(
|
||||
id="Dropdown_analysis_type",
|
||||
options=[
|
||||
{"label": v, "value": v}
|
||||
for v in SUMMARY_ANALYSIS_TYPE
|
||||
],
|
||||
value="summary_and_questions",
|
||||
clearable=False,
|
||||
style={
|
||||
"width": "100%",
|
||||
"minWidth": "240px",
|
||||
"maxWidth": "520px",
|
||||
},
|
||||
),
|
||||
),
|
||||
justify="start",
|
||||
),
|
||||
html.Div(style={"height": "8px"}),
|
||||
dbc.Row(
|
||||
[
|
||||
dbc.Col(
|
||||
dcc.Textarea(
|
||||
id="textarea_questions",
|
||||
value="Are there people in the image?\nWhat is this picture about?",
|
||||
placeholder="One question per line...",
|
||||
style={
|
||||
"width": "100%",
|
||||
"minHeight": "160px",
|
||||
"height": "220px",
|
||||
"resize": "vertical",
|
||||
"overflow": "auto",
|
||||
},
|
||||
rows=8,
|
||||
),
|
||||
width=12,
|
||||
),
|
||||
],
|
||||
justify="start",
|
||||
),
|
||||
]
|
||||
)
|
||||
],
|
||||
style={
|
||||
"width": "100%",
|
||||
"marginTop": "10px",
|
||||
"zIndex": 2000,
|
||||
},
|
||||
)
|
||||
],
|
||||
),
|
||||
],
|
||||
style={"width": "100%", "display": "inline-block"},
|
||||
style={"width": "100%", "display": "inline-block", "overflow": "visible"},
|
||||
)
|
||||
return settings_layout
|
||||
|
||||
@ -293,6 +357,7 @@ class AnalysisExplorer:
|
||||
"TextDetector",
|
||||
"EmotionDetector",
|
||||
"ColorDetector",
|
||||
"VQA",
|
||||
],
|
||||
value="TextDetector",
|
||||
id="Dropdown_select_Detector",
|
||||
@ -344,7 +409,7 @@ class AnalysisExplorer:
|
||||
port (int, optional): The port number to run the server on (default: 8050).
|
||||
"""
|
||||
|
||||
self.app.run_server(debug=True, port=port)
|
||||
self.app.run(debug=True, port=port)
|
||||
|
||||
# Dash callbacks
|
||||
def update_picture(self, img_path: str):
|
||||
@ -379,20 +444,27 @@ class AnalysisExplorer:
|
||||
|
||||
if setting_input == "EmotionDetector":
|
||||
return display_none, display_flex, display_none, display_none
|
||||
|
||||
if setting_input == "ColorDetector":
|
||||
return display_none, display_none, display_flex, display_none
|
||||
|
||||
if setting_input == "VQA":
|
||||
return display_none, display_none, display_none, display_flex
|
||||
else:
|
||||
return display_none, display_none, display_none, display_none
|
||||
|
||||
def _parse_questions(self, text: Optional[str]) -> Optional[List[str]]:
|
||||
if not text:
|
||||
return None
|
||||
qs = [q.strip() for q in text.splitlines() if q.strip()]
|
||||
return qs if qs else None
|
||||
|
||||
def _right_output_analysis(
|
||||
self,
|
||||
n_clicks,
|
||||
all_img_options: dict,
|
||||
current_img_value: str,
|
||||
detector_value: str,
|
||||
settings_text_analyse_text: list,
|
||||
analysis_type_value: str,
|
||||
textarea_questions_value: str,
|
||||
setting_privacy_env_var: str,
|
||||
setting_emotion_emotion_threshold: int,
|
||||
setting_emotion_race_threshold: int,
|
||||
@ -413,54 +485,71 @@ class AnalysisExplorer:
|
||||
"EmotionDetector": faces.EmotionDetector,
|
||||
"TextDetector": text.TextDetector,
|
||||
"ColorDetector": colors.ColorDetector,
|
||||
"VQA": image_summary.ImageSummaryDetector,
|
||||
}
|
||||
|
||||
# Get image ID from dropdown value, which is the filepath
|
||||
if current_img_value is None:
|
||||
return {}
|
||||
image_id = all_img_options[current_img_value]
|
||||
# copy image so prvious runs don't leave their default values in the dict
|
||||
image_copy = self.mydict[image_id].copy()
|
||||
image_copy = self.mydict.get(image_id, {}).copy()
|
||||
|
||||
# detector value is the string name of the chosen detector
|
||||
identify_function = identify_dict[detector_value]
|
||||
|
||||
if detector_value == "TextDetector":
|
||||
analyse_text = (
|
||||
True if settings_text_analyse_text == ["Analyse text"] else False
|
||||
)
|
||||
detector_class = identify_function(
|
||||
image_copy,
|
||||
analyse_text=analyse_text,
|
||||
accept_privacy=(
|
||||
setting_privacy_env_var
|
||||
if setting_privacy_env_var
|
||||
else "PRIVACY_AMMICO"
|
||||
),
|
||||
)
|
||||
elif detector_value == "EmotionDetector":
|
||||
detector_class = identify_function(
|
||||
image_copy,
|
||||
emotion_threshold=setting_emotion_emotion_threshold,
|
||||
race_threshold=setting_emotion_race_threshold,
|
||||
gender_threshold=setting_emotion_gender_threshold,
|
||||
accept_disclosure=(
|
||||
setting_emotion_env_var
|
||||
if setting_emotion_env_var
|
||||
else "DISCLOSURE_AMMICO"
|
||||
),
|
||||
)
|
||||
elif detector_value == "ColorDetector":
|
||||
detector_class = identify_function(
|
||||
image_copy,
|
||||
delta_e_method=setting_color_delta_e_method,
|
||||
)
|
||||
analysis_dict: Dict[str, Any] = {}
|
||||
if detector_value == "VQA":
|
||||
try:
|
||||
qwen_model = MultimodalSummaryModel(
|
||||
model_id="Qwen/Qwen2.5-VL-3B-Instruct"
|
||||
) # TODO: allow user to specify model
|
||||
vqa_cls = identify_dict.get("VQA")
|
||||
vqa_detector = vqa_cls(qwen_model, subdict={})
|
||||
questions_list = self._parse_questions(textarea_questions_value)
|
||||
analysis_result = vqa_detector.analyse_image(
|
||||
image_copy,
|
||||
analysis_type=analysis_type_value,
|
||||
list_of_questions=questions_list,
|
||||
is_concise_summary=True,
|
||||
is_concise_answer=True,
|
||||
)
|
||||
analysis_dict = analysis_result or {}
|
||||
except Exception as e:
|
||||
warnings.warn(f"VQA/Image tasks failed: {e}")
|
||||
analysis_dict = {"image_tasks_error": str(e)}
|
||||
else:
|
||||
detector_class = identify_function(image_copy)
|
||||
analysis_dict = detector_class.analyse_image()
|
||||
# detector value is the string name of the chosen detector
|
||||
identify_function = identify_dict[detector_value]
|
||||
|
||||
# Initialize an empty dictionary
|
||||
new_analysis_dict = {}
|
||||
if detector_value == "TextDetector":
|
||||
detector_class = identify_function(
|
||||
image_copy,
|
||||
accept_privacy=(
|
||||
setting_privacy_env_var
|
||||
if setting_privacy_env_var
|
||||
else "PRIVACY_AMMICO"
|
||||
),
|
||||
)
|
||||
elif detector_value == "EmotionDetector":
|
||||
detector_class = identify_function(
|
||||
image_copy,
|
||||
emotion_threshold=setting_emotion_emotion_threshold,
|
||||
race_threshold=setting_emotion_race_threshold,
|
||||
gender_threshold=setting_emotion_gender_threshold,
|
||||
accept_disclosure=(
|
||||
setting_emotion_env_var
|
||||
if setting_emotion_env_var
|
||||
else "DISCLOSURE_AMMICO"
|
||||
),
|
||||
)
|
||||
elif detector_value == "ColorDetector":
|
||||
detector_class = identify_function(
|
||||
image_copy,
|
||||
delta_e_method=setting_color_delta_e_method,
|
||||
)
|
||||
else:
|
||||
detector_class = identify_function(image_copy)
|
||||
|
||||
analysis_dict = detector_class.analyse_image()
|
||||
|
||||
new_analysis_dict: Dict[str, Any] = {}
|
||||
|
||||
# Iterate over the items in the original dictionary
|
||||
for k, v in analysis_dict.items():
|
||||
@ -480,3 +569,9 @@ class AnalysisExplorer:
|
||||
return dbc.Table.from_dataframe(
|
||||
df, striped=True, bordered=True, hover=True, index=True
|
||||
)
|
||||
|
||||
def _show_questions_textarea_on_demand(self, analysis_type_value: str) -> dict:
|
||||
if analysis_type_value in ("questions", "summary_and_questions"):
|
||||
return {"display": "block", "width": "100%"}
|
||||
else:
|
||||
return {"display": "none"}
|
||||
|
||||
@ -275,7 +275,6 @@ class EmotionDetector(AnalysisMethod):
|
||||
# one dictionary per face that is detected in the image
|
||||
# since we are only passing a subregion of the image
|
||||
# that contains one face, the list will only contain one dict
|
||||
print("actions are:", self.actions)
|
||||
if self.actions != []:
|
||||
fresult["result"] = DeepFace.analyze(
|
||||
img_path=face,
|
||||
|
||||
436
ammico/image_summary.py
Обычный файл
436
ammico/image_summary.py
Обычный файл
@ -0,0 +1,436 @@
|
||||
from ammico.utils import AnalysisMethod, AnalysisType
|
||||
from ammico.model import MultimodalSummaryModel
|
||||
|
||||
import os
|
||||
import torch
|
||||
from PIL import Image
|
||||
import warnings
|
||||
|
||||
from typing import List, Optional, Union, Dict, Any, Tuple
|
||||
from collections.abc import Sequence as _Sequence
|
||||
from transformers import GenerationConfig
|
||||
from qwen_vl_utils import process_vision_info
|
||||
|
||||
|
||||
class ImageSummaryDetector(AnalysisMethod):
|
||||
token_prompt_config = {
|
||||
"default": {
|
||||
"summary": {"prompt": "Describe this image.", "max_new_tokens": 256},
|
||||
"questions": {"prompt": "", "max_new_tokens": 128},
|
||||
},
|
||||
"concise": {
|
||||
"summary": {
|
||||
"prompt": "Describe this image in one concise caption.",
|
||||
"max_new_tokens": 64,
|
||||
},
|
||||
"questions": {"prompt": "Answer concisely: ", "max_new_tokens": 128},
|
||||
},
|
||||
}
|
||||
MAX_QUESTIONS_PER_IMAGE = 32
|
||||
KEYS_BATCH_SIZE = 16
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
summary_model: MultimodalSummaryModel,
|
||||
subdict: Optional[Dict[str, Any]] = None,
|
||||
) -> None:
|
||||
"""
|
||||
Class for analysing images using QWEN-2.5-VL model.
|
||||
It provides methods for generating captions and answering questions about images.
|
||||
|
||||
Args:
|
||||
summary_model ([type], optional): An instance of MultimodalSummaryModel to be used for analysis.
|
||||
subdict (dict, optional): Dictionary containing the image to be analysed. Defaults to {}.
|
||||
|
||||
Returns:
|
||||
None.
|
||||
"""
|
||||
if subdict is None:
|
||||
subdict = {}
|
||||
|
||||
super().__init__(subdict)
|
||||
self.summary_model = summary_model
|
||||
|
||||
def _load_pil_if_needed(
|
||||
self, filename: Union[str, os.PathLike, Image.Image]
|
||||
) -> Image.Image:
|
||||
if isinstance(filename, (str, os.PathLike)):
|
||||
return Image.open(filename).convert("RGB")
|
||||
elif isinstance(filename, Image.Image):
|
||||
return filename.convert("RGB")
|
||||
else:
|
||||
raise ValueError("filename must be a path or PIL.Image")
|
||||
|
||||
@staticmethod
|
||||
def _is_sequence_but_not_str(obj: Any) -> bool:
|
||||
"""True for sequence-like but not a string/bytes/PIL.Image."""
|
||||
return isinstance(obj, _Sequence) and not isinstance(
|
||||
obj, (str, bytes, Image.Image)
|
||||
)
|
||||
|
||||
def _prepare_inputs(
|
||||
self, list_of_questions: list[str], entry: Optional[Dict[str, Any]] = None
|
||||
) -> Dict[str, torch.Tensor]:
|
||||
filename = entry.get("filename")
|
||||
if filename is None:
|
||||
raise ValueError("entry must contain key 'filename'")
|
||||
|
||||
if isinstance(filename, (str, os.PathLike, Image.Image)):
|
||||
images_context = self._load_pil_if_needed(filename)
|
||||
elif self._is_sequence_but_not_str(filename):
|
||||
images_context = [self._load_pil_if_needed(i) for i in filename]
|
||||
else:
|
||||
raise ValueError(
|
||||
"Unsupported 'filename' entry: expected path, PIL.Image, or sequence."
|
||||
)
|
||||
|
||||
images_only_messages = [
|
||||
{
|
||||
"role": "user",
|
||||
"content": [
|
||||
*(
|
||||
[{"type": "image", "image": img} for img in images_context]
|
||||
if isinstance(images_context, list)
|
||||
else [{"type": "image", "image": images_context}]
|
||||
)
|
||||
],
|
||||
}
|
||||
]
|
||||
|
||||
try:
|
||||
image_inputs, _ = process_vision_info(images_only_messages)
|
||||
except Exception as e:
|
||||
raise RuntimeError(f"Image processing failed: {e}")
|
||||
|
||||
texts: List[str] = []
|
||||
for q in list_of_questions:
|
||||
messages = [
|
||||
{
|
||||
"role": "user",
|
||||
"content": [
|
||||
*(
|
||||
[
|
||||
{"type": "image", "image": image}
|
||||
for image in images_context
|
||||
]
|
||||
if isinstance(images_context, list)
|
||||
else [{"type": "image", "image": images_context}]
|
||||
),
|
||||
{"type": "text", "text": q},
|
||||
],
|
||||
}
|
||||
]
|
||||
text = self.summary_model.processor.apply_chat_template(
|
||||
messages, tokenize=False, add_generation_prompt=True
|
||||
)
|
||||
texts.append(text)
|
||||
|
||||
images_batch = [image_inputs] * len(texts)
|
||||
inputs = self.summary_model.processor(
|
||||
text=texts,
|
||||
images=images_batch,
|
||||
padding=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
inputs = {k: v.to(self.summary_model.device) for k, v in inputs.items()}
|
||||
|
||||
return inputs
|
||||
|
||||
def _validate_analysis_type(
|
||||
self,
|
||||
analysis_type: Union["AnalysisType", str],
|
||||
list_of_questions: Optional[List[str]],
|
||||
max_questions_per_image: int,
|
||||
) -> Tuple[str, List[str], bool, bool]:
|
||||
if isinstance(analysis_type, AnalysisType):
|
||||
analysis_type = analysis_type.value
|
||||
|
||||
allowed = {"summary", "questions", "summary_and_questions"}
|
||||
if analysis_type not in allowed:
|
||||
raise ValueError(f"analysis_type must be one of {allowed}")
|
||||
|
||||
if list_of_questions is None:
|
||||
list_of_questions = [
|
||||
"Are there people in the image?",
|
||||
"What is this picture about?",
|
||||
]
|
||||
|
||||
if analysis_type in ("questions", "summary_and_questions"):
|
||||
if len(list_of_questions) > max_questions_per_image:
|
||||
raise ValueError(
|
||||
f"Number of questions per image ({len(list_of_questions)}) exceeds safety cap ({max_questions_per_image}). Reduce questions or increase max_questions_per_image."
|
||||
)
|
||||
|
||||
is_summary = analysis_type in ("summary", "summary_and_questions")
|
||||
is_questions = analysis_type in ("questions", "summary_and_questions")
|
||||
|
||||
return analysis_type, list_of_questions, is_summary, is_questions
|
||||
|
||||
def analyse_image(
|
||||
self,
|
||||
entry: dict,
|
||||
analysis_type: Union[str, AnalysisType] = AnalysisType.SUMMARY_AND_QUESTIONS,
|
||||
list_of_questions: Optional[List[str]] = None,
|
||||
max_questions_per_image: int = MAX_QUESTIONS_PER_IMAGE,
|
||||
is_concise_summary: bool = True,
|
||||
is_concise_answer: bool = True,
|
||||
) -> Dict[str, Any]:
|
||||
"""
|
||||
Analyse a single image entry. Returns dict with keys depending on analysis_type:
|
||||
- 'caption' (str) if summary requested
|
||||
- 'vqa' (dict) if questions requested
|
||||
"""
|
||||
self.subdict = entry
|
||||
analysis_type, list_of_questions, is_summary, is_questions = (
|
||||
self._validate_analysis_type(
|
||||
analysis_type, list_of_questions, max_questions_per_image
|
||||
)
|
||||
)
|
||||
|
||||
if is_summary:
|
||||
try:
|
||||
caps = self.generate_caption(
|
||||
entry,
|
||||
num_return_sequences=1,
|
||||
is_concise_summary=is_concise_summary,
|
||||
)
|
||||
self.subdict["caption"] = caps[0] if caps else ""
|
||||
except Exception as e:
|
||||
warnings.warn(f"Caption generation failed: {e}")
|
||||
|
||||
if is_questions:
|
||||
try:
|
||||
vqa_map = self.answer_questions(
|
||||
list_of_questions, entry, is_concise_answer
|
||||
)
|
||||
self.subdict["vqa"] = vqa_map
|
||||
except Exception as e:
|
||||
warnings.warn(f"VQA failed: {e}")
|
||||
|
||||
return self.subdict
|
||||
|
||||
def analyse_images_from_dict(
|
||||
self,
|
||||
analysis_type: Union[AnalysisType, str] = AnalysisType.SUMMARY_AND_QUESTIONS,
|
||||
list_of_questions: Optional[List[str]] = None,
|
||||
max_questions_per_image: int = MAX_QUESTIONS_PER_IMAGE,
|
||||
keys_batch_size: int = KEYS_BATCH_SIZE,
|
||||
is_concise_summary: bool = True,
|
||||
is_concise_answer: bool = True,
|
||||
) -> Dict[str, dict]:
|
||||
"""
|
||||
Analyse image with model.
|
||||
|
||||
Args:
|
||||
analysis_type (str): type of the analysis.
|
||||
list_of_questions (list[str]): list of questions.
|
||||
max_questions_per_image (int): maximum number of questions per image. We recommend to keep it low to avoid long processing times and high memory usage.
|
||||
keys_batch_size (int): number of images to process in a batch.
|
||||
is_concise_summary (bool): whether to generate concise summary.
|
||||
is_concise_answer (bool): whether to generate concise answers.
|
||||
Returns:
|
||||
self.subdict (dict): dictionary with analysis results.
|
||||
"""
|
||||
# TODO: add option to ask multiple questions per image as one batch.
|
||||
analysis_type, list_of_questions, is_summary, is_questions = (
|
||||
self._validate_analysis_type(
|
||||
analysis_type, list_of_questions, max_questions_per_image
|
||||
)
|
||||
)
|
||||
|
||||
keys = list(self.subdict.keys())
|
||||
for batch_start in range(0, len(keys), keys_batch_size):
|
||||
batch_keys = keys[batch_start : batch_start + keys_batch_size]
|
||||
for key in batch_keys:
|
||||
entry = self.subdict[key]
|
||||
if is_summary:
|
||||
try:
|
||||
caps = self.generate_caption(
|
||||
entry,
|
||||
num_return_sequences=1,
|
||||
is_concise_summary=is_concise_summary,
|
||||
)
|
||||
entry["caption"] = caps[0] if caps else ""
|
||||
except Exception as e:
|
||||
warnings.warn(f"Caption generation failed: {e}")
|
||||
|
||||
if is_questions:
|
||||
try:
|
||||
vqa_map = self.answer_questions(
|
||||
list_of_questions, entry, is_concise_answer
|
||||
)
|
||||
entry["vqa"] = vqa_map
|
||||
except Exception as e:
|
||||
warnings.warn(f"VQA failed: {e}")
|
||||
|
||||
self.subdict[key] = entry
|
||||
return self.subdict
|
||||
|
||||
def generate_caption(
|
||||
self,
|
||||
entry: Optional[Dict[str, Any]] = None,
|
||||
num_return_sequences: int = 1,
|
||||
is_concise_summary: bool = True,
|
||||
) -> List[str]:
|
||||
"""
|
||||
Create caption for image. Depending on is_concise_summary it will be either concise or detailed.
|
||||
|
||||
Args:
|
||||
entry (dict): dictionary containing the image to be captioned.
|
||||
num_return_sequences (int): number of captions to generate.
|
||||
is_concise_summary (bool): whether to generate concise summary.
|
||||
|
||||
Returns:
|
||||
results (list[str]): list of generated captions.
|
||||
"""
|
||||
prompt = self.token_prompt_config[
|
||||
"concise" if is_concise_summary else "default"
|
||||
]["summary"]["prompt"]
|
||||
max_new_tokens = self.token_prompt_config[
|
||||
"concise" if is_concise_summary else "default"
|
||||
]["summary"]["max_new_tokens"]
|
||||
inputs = self._prepare_inputs([prompt], entry)
|
||||
|
||||
gen_conf = GenerationConfig(
|
||||
max_new_tokens=max_new_tokens,
|
||||
do_sample=False,
|
||||
num_return_sequences=num_return_sequences,
|
||||
)
|
||||
|
||||
with torch.inference_mode():
|
||||
try:
|
||||
if self.summary_model.device == "cuda":
|
||||
with torch.cuda.amp.autocast(enabled=True):
|
||||
generated_ids = self.summary_model.model.generate(
|
||||
**inputs, generation_config=gen_conf
|
||||
)
|
||||
else:
|
||||
generated_ids = self.summary_model.model.generate(
|
||||
**inputs, generation_config=gen_conf
|
||||
)
|
||||
except RuntimeError as e:
|
||||
warnings.warn(
|
||||
f"Retry without autocast failed: {e}. Attempting cudnn-disabled retry."
|
||||
)
|
||||
cudnn_was_enabled = (
|
||||
torch.backends.cudnn.is_available() and torch.backends.cudnn.enabled
|
||||
)
|
||||
if cudnn_was_enabled:
|
||||
torch.backends.cudnn.enabled = False
|
||||
try:
|
||||
generated_ids = self.summary_model.model.generate(
|
||||
**inputs, generation_config=gen_conf
|
||||
)
|
||||
except Exception as retry_error:
|
||||
raise RuntimeError(
|
||||
f"Failed to generate ids after retry: {retry_error}"
|
||||
) from retry_error
|
||||
finally:
|
||||
if cudnn_was_enabled:
|
||||
torch.backends.cudnn.enabled = True
|
||||
|
||||
decoded = None
|
||||
if "input_ids" in inputs:
|
||||
in_ids = inputs["input_ids"]
|
||||
trimmed = [
|
||||
out_ids[len(inp_ids) :]
|
||||
for inp_ids, out_ids in zip(in_ids, generated_ids)
|
||||
]
|
||||
decoded = self.summary_model.tokenizer.batch_decode(
|
||||
trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
||||
)
|
||||
else:
|
||||
decoded = self.summary_model.tokenizer.batch_decode(
|
||||
generated_ids,
|
||||
skip_special_tokens=True,
|
||||
clean_up_tokenization_spaces=False,
|
||||
)
|
||||
|
||||
results = [d.strip() for d in decoded]
|
||||
return results
|
||||
|
||||
def _clean_list_of_questions(
|
||||
self, list_of_questions: list[str], prompt: str
|
||||
) -> list[str]:
|
||||
"""Clean the list of questions to contain correctly formatted strings."""
|
||||
# remove all None or empty questions
|
||||
list_of_questions = [i for i in list_of_questions if i and i.strip()]
|
||||
# ensure each question ends with a question mark
|
||||
list_of_questions = [
|
||||
i.strip() + "?" if not i.strip().endswith("?") else i.strip()
|
||||
for i in list_of_questions
|
||||
]
|
||||
# ensure each question starts with the prompt
|
||||
list_of_questions = [
|
||||
i if i.lower().startswith(prompt.lower()) else prompt + i
|
||||
for i in list_of_questions
|
||||
]
|
||||
return list_of_questions
|
||||
|
||||
def answer_questions(
|
||||
self,
|
||||
list_of_questions: list[str],
|
||||
entry: Optional[Dict[str, Any]] = None,
|
||||
is_concise_answer: bool = True,
|
||||
) -> List[str]:
|
||||
"""
|
||||
Create answers for list of questions about image.
|
||||
Args:
|
||||
list_of_questions (list[str]): list of questions.
|
||||
entry (dict): dictionary containing the image to be captioned.
|
||||
is_concise_answer (bool): whether to generate concise answers.
|
||||
Returns:
|
||||
answers (list[str]): list of answers.
|
||||
"""
|
||||
prompt = self.token_prompt_config[
|
||||
"concise" if is_concise_answer else "default"
|
||||
]["questions"]["prompt"]
|
||||
max_new_tokens = self.token_prompt_config[
|
||||
"concise" if is_concise_answer else "default"
|
||||
]["questions"]["max_new_tokens"]
|
||||
|
||||
list_of_questions = self._clean_list_of_questions(list_of_questions, prompt)
|
||||
gen_conf = GenerationConfig(max_new_tokens=max_new_tokens, do_sample=False)
|
||||
|
||||
question_chunk_size = 8
|
||||
answers: List[str] = []
|
||||
n = len(list_of_questions)
|
||||
for i in range(0, n, question_chunk_size):
|
||||
chunk = list_of_questions[i : i + question_chunk_size]
|
||||
inputs = self._prepare_inputs(chunk, entry)
|
||||
with torch.inference_mode():
|
||||
if self.summary_model.device == "cuda":
|
||||
with torch.cuda.amp.autocast(enabled=True):
|
||||
out_ids = self.summary_model.model.generate(
|
||||
**inputs, generation_config=gen_conf
|
||||
)
|
||||
else:
|
||||
out_ids = self.summary_model.model.generate(
|
||||
**inputs, generation_config=gen_conf
|
||||
)
|
||||
|
||||
if "input_ids" in inputs:
|
||||
in_ids = inputs["input_ids"]
|
||||
trimmed_batch = [
|
||||
out_row[len(inp_row) :] for inp_row, out_row in zip(in_ids, out_ids)
|
||||
]
|
||||
decoded = self.summary_model.tokenizer.batch_decode(
|
||||
trimmed_batch,
|
||||
skip_special_tokens=True,
|
||||
clean_up_tokenization_spaces=False,
|
||||
)
|
||||
else:
|
||||
decoded = self.summary_model.tokenizer.batch_decode(
|
||||
out_ids,
|
||||
skip_special_tokens=True,
|
||||
clean_up_tokenization_spaces=False,
|
||||
)
|
||||
|
||||
answers.extend([d.strip() for d in decoded])
|
||||
|
||||
if len(answers) != len(list_of_questions):
|
||||
raise ValueError(
|
||||
f"Expected {len(list_of_questions)} answers, but got {len(answers)}, try varying amount of questions"
|
||||
)
|
||||
|
||||
return answers
|
||||
122
ammico/model.py
Обычный файл
122
ammico/model.py
Обычный файл
@ -0,0 +1,122 @@
|
||||
import torch
|
||||
import warnings
|
||||
from transformers import (
|
||||
Qwen2_5_VLForConditionalGeneration,
|
||||
AutoProcessor,
|
||||
BitsAndBytesConfig,
|
||||
AutoTokenizer,
|
||||
)
|
||||
from typing import Optional
|
||||
|
||||
|
||||
class MultimodalSummaryModel:
|
||||
DEFAULT_CUDA_MODEL = "Qwen/Qwen2.5-VL-7B-Instruct"
|
||||
DEFAULT_CPU_MODEL = "Qwen/Qwen2.5-VL-3B-Instruct"
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model_id: Optional[str] = None,
|
||||
device: Optional[str] = None,
|
||||
cache_dir: Optional[str] = None,
|
||||
) -> None:
|
||||
"""
|
||||
Class for QWEN-2.5-VL model loading and inference.
|
||||
Args:
|
||||
model_id: Type of model to load, defaults to a smaller version for CPU if device is "cpu".
|
||||
device: "cuda" or "cpu" (auto-detected when None).
|
||||
cache_dir: huggingface cache dir (optional).
|
||||
"""
|
||||
self.device = self._resolve_device(device)
|
||||
|
||||
if model_id is not None and model_id not in (
|
||||
self.DEFAULT_CUDA_MODEL,
|
||||
self.DEFAULT_CPU_MODEL,
|
||||
):
|
||||
raise ValueError(
|
||||
f"model_id must be one of {self.DEFAULT_CUDA_MODEL} or {self.DEFAULT_CPU_MODEL}"
|
||||
)
|
||||
|
||||
self.model_id = model_id or (
|
||||
self.DEFAULT_CUDA_MODEL if self.device == "cuda" else self.DEFAULT_CPU_MODEL
|
||||
)
|
||||
|
||||
self.cache_dir = cache_dir
|
||||
self._trust_remote_code = True
|
||||
self._quantize = True
|
||||
|
||||
self.model = None
|
||||
self.processor = None
|
||||
self.tokenizer = None
|
||||
|
||||
self._load_model_and_processor()
|
||||
|
||||
@staticmethod
|
||||
def _resolve_device(device: Optional[str]) -> str:
|
||||
if device is None:
|
||||
return "cuda" if torch.cuda.is_available() else "cpu"
|
||||
if device.lower() not in ("cuda", "cpu"):
|
||||
raise ValueError("device must be 'cuda' or 'cpu'")
|
||||
if device.lower() == "cuda" and not torch.cuda.is_available():
|
||||
warnings.warn(
|
||||
"Although 'cuda' was requested, no CUDA device is available. Using CPU instead.",
|
||||
RuntimeWarning,
|
||||
stacklevel=2,
|
||||
)
|
||||
return "cpu"
|
||||
return device.lower()
|
||||
|
||||
def _load_model_and_processor(self):
|
||||
load_kwargs = {"trust_remote_code": self._trust_remote_code, "use_cache": True}
|
||||
if self.cache_dir:
|
||||
load_kwargs["cache_dir"] = self.cache_dir
|
||||
|
||||
self.processor = AutoProcessor.from_pretrained(
|
||||
self.model_id, padding_side="left", **load_kwargs
|
||||
)
|
||||
self.tokenizer = AutoTokenizer.from_pretrained(self.model_id, **load_kwargs)
|
||||
|
||||
if self.device == "cuda":
|
||||
compute_dtype = (
|
||||
torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16
|
||||
)
|
||||
bnb_config = BitsAndBytesConfig(
|
||||
load_in_4bit=True,
|
||||
bnb_4bit_use_double_quant=True,
|
||||
bnb_4bit_quant_type="nf4",
|
||||
bnb_4bit_compute_dtype=compute_dtype,
|
||||
)
|
||||
load_kwargs["quantization_config"] = bnb_config
|
||||
load_kwargs["device_map"] = "auto"
|
||||
|
||||
else:
|
||||
load_kwargs.pop("quantization_config", None)
|
||||
load_kwargs.pop("device_map", None)
|
||||
|
||||
self.model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
|
||||
self.model_id, **load_kwargs
|
||||
)
|
||||
self.model.eval()
|
||||
|
||||
def close(self) -> None:
|
||||
"""Free model resources (helpful in long-running processes)."""
|
||||
try:
|
||||
if self.model is not None:
|
||||
del self.model
|
||||
self.model = None
|
||||
if self.processor is not None:
|
||||
del self.processor
|
||||
self.processor = None
|
||||
if self.tokenizer is not None:
|
||||
del self.tokenizer
|
||||
self.tokenizer = None
|
||||
finally:
|
||||
try:
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
except Exception as e:
|
||||
warnings.warn(
|
||||
"Failed to empty CUDA cache. This is not critical, but may lead to memory lingering: "
|
||||
f"{e!r}",
|
||||
RuntimeWarning,
|
||||
stacklevel=2,
|
||||
)
|
||||
200
ammico/notebooks/DemoImageSummaryVQA.ipynb
Обычный файл
200
ammico/notebooks/DemoImageSummaryVQA.ipynb
Обычный файл
@ -0,0 +1,200 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "0",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Image summary and visual question answering"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This notebook shows how to generate image captions and use the visual question answering with AMMICO. \n",
|
||||
"\n",
|
||||
"The first cell imports `ammico`.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "2",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import ammico"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "3",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The cell below loads the model for VQA tasks. By default, it loads a large model on the GPU (if your device supports CUDA), otherwise it loads a relatively smaller model on the CPU. But you can specify other settings (e.g., a small model on the GPU) if you want."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "4",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"model = ammico.MultimodalSummaryModel()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Here you need to provide the path to your google drive folder or local folder containing the images"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "6",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"image_dict = ammico.find_files(\n",
|
||||
" path=str(\"../../data/in\"),\n",
|
||||
" limit=-1, # -1 means no limit on the number of files, by default it is set to 20\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "7",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The cell below creates an object that analyzes images and generates a summary using a specific model and image data."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"img = ammico.ImageSummaryDetector(summary_model=model, subdict=image_dict)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Image summary "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "10",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"To start your work with images, you should call the `analyse_images` method.\n",
|
||||
"\n",
|
||||
"You can specify what kind of analysis you want to perform with `analysis_type`. `\"summary\"` will generate a summary for all pictures in your dictionary, `\"questions\"` will prepare answers to your questions for all pictures, and `\"summary_and_questions\"` will do both.\n",
|
||||
"\n",
|
||||
"Parameter `\"is_concise_summary\"` regulates the length of an answer.\n",
|
||||
"\n",
|
||||
"Here we want to get a long summary on each object in our image dictionary."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "11",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"summaries = img.analyse_images_from_dict(\n",
|
||||
" analysis_type=\"summary\", is_concise_summary=False\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "12",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## VQA"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "13",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"In addition to analyzing images in `ammico`, the same model can be used in VQA mode. To do this, you need to define the questions that will be applied to all images from your dict."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "14",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"questions = [\"Are there any visible signs of violence?\", \"Is it safe to be there?\"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "15",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Here is an example of VQA mode usage. You can specify whether you want to receive short answers (recommended option) or not."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "16",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"vqa_results = img.analyse_images_from_dict(\n",
|
||||
" analysis_type=\"questions\",\n",
|
||||
" list_of_questions=questions,\n",
|
||||
" is_concise_answer=True,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "17",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "ammico",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.14"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
Разница между файлами не показана из-за своего большого размера
Загрузить разницу
@ -1,5 +1,7 @@
|
||||
import os
|
||||
import pytest
|
||||
from ammico.model import MultimodalSummaryModel
|
||||
import torch
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
@ -46,3 +48,72 @@ def get_test_my_dict(get_path):
|
||||
},
|
||||
}
|
||||
return test_my_dict
|
||||
|
||||
|
||||
@pytest.fixture(scope="session")
|
||||
def model():
|
||||
m = MultimodalSummaryModel(device="cpu")
|
||||
try:
|
||||
yield m
|
||||
finally:
|
||||
m.close()
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def mock_model():
|
||||
"""
|
||||
Mock model fixture that doesn't load the actual model.
|
||||
Useful for faster unit tests that don't need actual model inference.
|
||||
"""
|
||||
|
||||
class MockProcessor:
|
||||
"""Mock processor that mimics AutoProcessor behavior."""
|
||||
|
||||
def apply_chat_template(self, messages, **kwargs):
|
||||
return "processed_text"
|
||||
|
||||
def __call__(self, text, images, **kwargs):
|
||||
"""Mock processing that returns tensor-like inputs."""
|
||||
batch_size = len(text) if isinstance(text, list) else 1
|
||||
return {
|
||||
"input_ids": torch.randint(0, 1000, (batch_size, 10)),
|
||||
"pixel_values": torch.randn(batch_size, 3, 224, 224),
|
||||
"attention_mask": torch.ones(batch_size, 10),
|
||||
}
|
||||
|
||||
class MockTokenizer:
|
||||
"""Mock tokenizer that mimics AutoTokenizer behavior."""
|
||||
|
||||
def batch_decode(self, ids, **kwargs):
|
||||
"""Return mock captions for the given batch size."""
|
||||
batch_size = ids.shape[0] if hasattr(ids, "shape") else len(ids)
|
||||
return ["mock caption" for _ in range(batch_size)]
|
||||
|
||||
class MockModelObj:
|
||||
"""Mock model object that mimics the model.generate behavior."""
|
||||
|
||||
def __init__(self):
|
||||
self.device = "cpu"
|
||||
|
||||
def eval(self):
|
||||
return self
|
||||
|
||||
def generate(self, input_ids=None, **kwargs):
|
||||
"""Generate mock token IDs."""
|
||||
batch_size = input_ids.shape[0] if hasattr(input_ids, "shape") else 1
|
||||
return torch.randint(0, 1000, (batch_size, 20))
|
||||
|
||||
class MockMultimodalSummaryModel:
|
||||
"""Mock MultimodalSummaryModel that doesn't load actual models."""
|
||||
|
||||
def __init__(self):
|
||||
self.model = MockModelObj()
|
||||
self.processor = MockProcessor()
|
||||
self.tokenizer = MockTokenizer()
|
||||
self.device = "cpu"
|
||||
|
||||
def close(self):
|
||||
"""Mock close method - no actual cleanup needed."""
|
||||
pass
|
||||
|
||||
return MockMultimodalSummaryModel()
|
||||
|
||||
@ -50,7 +50,8 @@ def test_right_output_analysis_emotions(get_AE, get_options, monkeypatch):
|
||||
get_options[3],
|
||||
get_options[0],
|
||||
"EmotionDetector",
|
||||
True,
|
||||
"summary",
|
||||
"Some question",
|
||||
"SOME_VAR",
|
||||
50,
|
||||
50,
|
||||
|
||||
122
ammico/test/test_image_summary.py
Обычный файл
122
ammico/test/test_image_summary.py
Обычный файл
@ -0,0 +1,122 @@
|
||||
from ammico.image_summary import ImageSummaryDetector
|
||||
import os
|
||||
from PIL import Image
|
||||
import pytest
|
||||
|
||||
|
||||
@pytest.mark.long
|
||||
def test_image_summary_detector(model, get_testdict):
|
||||
detector = ImageSummaryDetector(summary_model=model, subdict=get_testdict)
|
||||
results = detector.analyse_images_from_dict(analysis_type="summary")
|
||||
assert len(results) == 2
|
||||
for key in get_testdict.keys():
|
||||
assert key in results
|
||||
assert "caption" in results[key]
|
||||
assert isinstance(results[key]["caption"], str)
|
||||
assert len(results[key]["caption"]) > 0
|
||||
|
||||
|
||||
@pytest.mark.long
|
||||
def test_image_summary_detector_questions(model, get_testdict):
|
||||
list_of_questions = [
|
||||
"What is happening in the image?",
|
||||
"How many cars are in the image in total?",
|
||||
]
|
||||
detector = ImageSummaryDetector(summary_model=model, subdict=get_testdict)
|
||||
results = detector.analyse_images_from_dict(
|
||||
analysis_type="questions", list_of_questions=list_of_questions
|
||||
)
|
||||
assert len(results) == 2
|
||||
for key in get_testdict.keys():
|
||||
assert "vqa" in results[key]
|
||||
if key == "IMG_2746":
|
||||
assert "marathon" in results[key]["vqa"][0].lower()
|
||||
|
||||
if key == "IMG_2809":
|
||||
assert (
|
||||
"two" in results[key]["vqa"][1].lower() or "2" in results[key]["vqa"][1]
|
||||
)
|
||||
|
||||
|
||||
def test_clean_list_of_questions(mock_model):
|
||||
list_of_questions = [
|
||||
"What is happening in the image?",
|
||||
"",
|
||||
" ",
|
||||
None,
|
||||
"How many cars are in the image in total",
|
||||
]
|
||||
detector = ImageSummaryDetector(summary_model=mock_model, subdict={})
|
||||
prompt = detector.token_prompt_config["default"]["questions"]["prompt"]
|
||||
cleaned_questions = detector._clean_list_of_questions(list_of_questions, prompt)
|
||||
assert len(cleaned_questions) == 2
|
||||
assert cleaned_questions[0] == "What is happening in the image?"
|
||||
assert cleaned_questions[1] == "How many cars are in the image in total?"
|
||||
prompt = detector.token_prompt_config["concise"]["questions"]["prompt"]
|
||||
cleaned_questions = detector._clean_list_of_questions(list_of_questions, prompt)
|
||||
assert len(cleaned_questions) == 2
|
||||
assert cleaned_questions[0] == prompt + "What is happening in the image?"
|
||||
assert cleaned_questions[1] == prompt + "How many cars are in the image in total?"
|
||||
|
||||
|
||||
# Fast tests using mock model (no actual model loading)
|
||||
def test_image_summary_detector_init_mock(mock_model, get_testdict):
|
||||
"""Test detector initialization with mocked model."""
|
||||
detector = ImageSummaryDetector(summary_model=mock_model, subdict=get_testdict)
|
||||
assert detector.summary_model is mock_model
|
||||
assert len(detector.subdict) == 2
|
||||
|
||||
|
||||
def test_load_pil_if_needed_string(mock_model):
|
||||
"""Test loading image from file path."""
|
||||
detector = ImageSummaryDetector(summary_model=mock_model)
|
||||
# This will try to actually load a file, so we'll use a test image
|
||||
test_image_path = os.path.join(os.path.dirname(__file__), "data", "IMG_2746.png")
|
||||
if os.path.exists(test_image_path):
|
||||
img = detector._load_pil_if_needed(test_image_path)
|
||||
assert isinstance(img, Image.Image)
|
||||
assert img.mode == "RGB"
|
||||
|
||||
|
||||
def test_is_sequence_but_not_str(mock_model):
|
||||
"""Test sequence detection utility."""
|
||||
detector = ImageSummaryDetector(summary_model=mock_model)
|
||||
assert detector._is_sequence_but_not_str([1, 2, 3]) is True
|
||||
assert detector._is_sequence_but_not_str("string") is False
|
||||
assert detector._is_sequence_but_not_str(b"bytes") is False
|
||||
assert (
|
||||
detector._is_sequence_but_not_str({"a": 1}) is False
|
||||
) # dict is sequence-like but not handled as such
|
||||
|
||||
|
||||
def test_validate_analysis_type(mock_model):
|
||||
"""Test analysis type validation."""
|
||||
detector = ImageSummaryDetector(summary_model=mock_model)
|
||||
# Test valid types
|
||||
_, _, is_summary, is_questions = detector._validate_analysis_type(
|
||||
"summary", None, 10
|
||||
)
|
||||
assert is_summary is True
|
||||
assert is_questions is False
|
||||
|
||||
_, _, is_summary, is_questions = detector._validate_analysis_type(
|
||||
"questions", ["What is this?"], 10
|
||||
)
|
||||
assert is_summary is False
|
||||
assert is_questions is True
|
||||
|
||||
_, _, is_summary, is_questions = detector._validate_analysis_type(
|
||||
"summary_and_questions", ["What is this?"], 10
|
||||
)
|
||||
assert is_summary is True
|
||||
assert is_questions is True
|
||||
|
||||
# Test invalid type
|
||||
with pytest.raises(ValueError):
|
||||
detector._validate_analysis_type("invalid", None, 10)
|
||||
|
||||
# Test too many questions
|
||||
with pytest.raises(ValueError):
|
||||
detector._validate_analysis_type(
|
||||
"questions", ["Q" + str(i) for i in range(33)], 32
|
||||
)
|
||||
30
ammico/test/test_model.py
Обычный файл
30
ammico/test/test_model.py
Обычный файл
@ -0,0 +1,30 @@
|
||||
import pytest
|
||||
from ammico.model import MultimodalSummaryModel
|
||||
|
||||
|
||||
@pytest.mark.long
|
||||
def test_model_init(model):
|
||||
assert model.model is not None
|
||||
assert model.processor is not None
|
||||
assert model.tokenizer is not None
|
||||
assert model.device is not None
|
||||
|
||||
|
||||
@pytest.mark.long
|
||||
def test_model_invalid_device():
|
||||
with pytest.raises(ValueError):
|
||||
MultimodalSummaryModel(device="invalid_device")
|
||||
|
||||
|
||||
@pytest.mark.long
|
||||
def test_model_invalid_model_id():
|
||||
with pytest.raises(ValueError):
|
||||
MultimodalSummaryModel(model_id="non_existent_model", device="cpu")
|
||||
|
||||
|
||||
@pytest.mark.long
|
||||
def test_free_resources():
|
||||
model = MultimodalSummaryModel(device="cpu")
|
||||
model.close()
|
||||
assert model.model is None
|
||||
assert model.processor is None
|
||||
@ -52,24 +52,16 @@ def test_privacy_statement(monkeypatch):
|
||||
def test_TextDetector(set_testdict, accepted):
|
||||
for item in set_testdict:
|
||||
test_obj = tt.TextDetector(set_testdict[item], accept_privacy=accepted)
|
||||
assert not test_obj.analyse_text
|
||||
assert not test_obj.skip_extraction
|
||||
assert test_obj.subdict["filename"] == set_testdict[item]["filename"]
|
||||
test_obj = tt.TextDetector(
|
||||
{}, analyse_text=True, skip_extraction=True, accept_privacy=accepted
|
||||
)
|
||||
assert test_obj.analyse_text
|
||||
test_obj = tt.TextDetector({}, skip_extraction=True, accept_privacy=accepted)
|
||||
assert test_obj.skip_extraction
|
||||
with pytest.raises(ValueError):
|
||||
tt.TextDetector({}, analyse_text=1.0, accept_privacy=accepted)
|
||||
with pytest.raises(ValueError):
|
||||
tt.TextDetector({}, skip_extraction=1.0, accept_privacy=accepted)
|
||||
|
||||
|
||||
def test_run_spacy(set_testdict, get_path, accepted):
|
||||
test_obj = tt.TextDetector(
|
||||
set_testdict["IMG_3755"], analyse_text=True, accept_privacy=accepted
|
||||
)
|
||||
test_obj = tt.TextDetector(set_testdict["IMG_3755"], accept_privacy=accepted)
|
||||
ref_file = get_path + "text_IMG_3755.txt"
|
||||
with open(ref_file, "r") as file:
|
||||
reference_text = file.read()
|
||||
@ -108,15 +100,11 @@ def test_analyse_image(set_testdict, set_environ, accepted):
|
||||
for item in set_testdict:
|
||||
test_obj = tt.TextDetector(set_testdict[item], accept_privacy=accepted)
|
||||
test_obj.analyse_image()
|
||||
test_obj = tt.TextDetector(
|
||||
set_testdict[item], analyse_text=True, accept_privacy=accepted
|
||||
)
|
||||
test_obj = tt.TextDetector(set_testdict[item], accept_privacy=accepted)
|
||||
test_obj.analyse_image()
|
||||
testdict = {}
|
||||
testdict["text"] = 20000 * "m"
|
||||
test_obj = tt.TextDetector(
|
||||
testdict, skip_extraction=True, analyse_text=True, accept_privacy=accepted
|
||||
)
|
||||
test_obj = tt.TextDetector(testdict, skip_extraction=True, accept_privacy=accepted)
|
||||
test_obj.analyse_image()
|
||||
assert test_obj.subdict["text_truncated"] == 5000 * "m"
|
||||
assert test_obj.subdict["text"] == 20000 * "m"
|
||||
|
||||
@ -67,7 +67,6 @@ class TextDetector(AnalysisMethod):
|
||||
def __init__(
|
||||
self,
|
||||
subdict: dict,
|
||||
analyse_text: bool = False,
|
||||
skip_extraction: bool = False,
|
||||
accept_privacy: str = "PRIVACY_AMMICO",
|
||||
) -> None:
|
||||
@ -76,8 +75,6 @@ class TextDetector(AnalysisMethod):
|
||||
Args:
|
||||
subdict (dict): Dictionary containing file name/path, and possibly previous
|
||||
analysis results from other modules.
|
||||
analyse_text (bool, optional): Decide if extracted text will be further subject
|
||||
to analysis. Defaults to False.
|
||||
skip_extraction (bool, optional): Decide if text will be extracted from images or
|
||||
is already provided via a csv. Defaults to False.
|
||||
accept_privacy (str, optional): Environment variable to accept the privacy
|
||||
@ -96,17 +93,13 @@ class TextDetector(AnalysisMethod):
|
||||
"Privacy disclosure not accepted - skipping text detection."
|
||||
)
|
||||
self.translator = Translator(raise_exception=True)
|
||||
if not isinstance(analyse_text, bool):
|
||||
raise ValueError("analyse_text needs to be set to true or false")
|
||||
self.analyse_text = analyse_text
|
||||
self.skip_extraction = skip_extraction
|
||||
if not isinstance(skip_extraction, bool):
|
||||
raise ValueError("skip_extraction needs to be set to true or false")
|
||||
if self.skip_extraction:
|
||||
print("Skipping text extraction from image.")
|
||||
print("Reading text directly from provided dictionary.")
|
||||
if self.analyse_text:
|
||||
self._initialize_spacy()
|
||||
self._initialize_spacy()
|
||||
|
||||
def set_keys(self) -> dict:
|
||||
"""Set the default keys for text analysis.
|
||||
@ -183,7 +176,7 @@ class TextDetector(AnalysisMethod):
|
||||
self._truncate_text()
|
||||
self.translate_text()
|
||||
self.remove_linebreaks()
|
||||
if self.analyse_text and self.subdict["text_english"]:
|
||||
if self.subdict["text_english"]:
|
||||
self._run_spacy()
|
||||
return self.subdict
|
||||
|
||||
|
||||
@ -7,6 +7,9 @@ import collections
|
||||
import random
|
||||
|
||||
|
||||
from enum import Enum
|
||||
|
||||
|
||||
pkg = importlib_resources.files("ammico")
|
||||
|
||||
|
||||
@ -40,6 +43,12 @@ def ammico_prefetch_models():
|
||||
res.get()
|
||||
|
||||
|
||||
class AnalysisType(str, Enum):
|
||||
SUMMARY = "summary"
|
||||
QUESTIONS = "questions"
|
||||
SUMMARY_AND_QUESTIONS = "summary_and_questions"
|
||||
|
||||
|
||||
class AnalysisMethod:
|
||||
"""Base class to be inherited by all analysis methods."""
|
||||
|
||||
|
||||
19
environment.yml
Обычный файл
19
environment.yml
Обычный файл
@ -0,0 +1,19 @@
|
||||
name: ammico-dev
|
||||
channels:
|
||||
- pytorch
|
||||
- nvidia
|
||||
- rapidsai
|
||||
- conda-forge
|
||||
- defaults
|
||||
|
||||
dependencies:
|
||||
- python=3.11
|
||||
- cudatoolkit=11.8
|
||||
- pytorch=2.3.1
|
||||
- pytorch-cuda=11.8
|
||||
- torchvision=0.18.1
|
||||
- torchaudio=2.3.1
|
||||
- faiss-gpu-raft=1.8.0
|
||||
- ipykernel
|
||||
- jupyterlab
|
||||
- jupyterlab_widgets
|
||||
@ -18,30 +18,37 @@ classifiers = [
|
||||
"Operating System :: OS Independent",
|
||||
"License :: OSI Approved :: MIT License",
|
||||
]
|
||||
|
||||
|
||||
dependencies = [
|
||||
"accelerate>=0.22",
|
||||
"bitsandbytes",
|
||||
"colorgram.py",
|
||||
"colour-science",
|
||||
"dash",
|
||||
"dash-bootstrap-components",
|
||||
"deepface",
|
||||
"google-cloud-vision",
|
||||
"googletrans==4.0.0rc1",
|
||||
"googletrans-py", # instead of googletrans4.0.0rc1, for a temporary solution due to incompatibility with jupyterlab
|
||||
"grpcio",
|
||||
"huggingface-hub>=0.34.0",
|
||||
"importlib_metadata",
|
||||
"importlib_resources",
|
||||
"matplotlib",
|
||||
"numpy",
|
||||
"numpy==1.23.5",
|
||||
"opencv-python",
|
||||
"pandas",
|
||||
"Pillow",
|
||||
"pooch",
|
||||
"qwen-vl-utils",
|
||||
"retina_face",
|
||||
"safetensors>=0.6.2",
|
||||
"setuptools",
|
||||
"spacy",
|
||||
"tensorflow<=2.16.0",
|
||||
"tensorflow<2.15", # instead of <=2.16.0 to make it compatible with CUDA 11.8, may change after updating CUDA version.
|
||||
"tf-keras",
|
||||
"torchvision",
|
||||
"tqdm",
|
||||
"transformers>=4.54",
|
||||
"webcolors",
|
||||
]
|
||||
|
||||
@ -62,6 +69,7 @@ nb = [
|
||||
"datasets",
|
||||
"huggingface-hub",
|
||||
"ipython",
|
||||
"ipykernel<=6.30.1",
|
||||
"jupyter",
|
||||
"jupyter_dash",
|
||||
]
|
||||
|
||||
Загрузка…
x
Ссылка в новой задаче
Block a user