Сравнить коммиты
Нет общих коммитов. «archive/ref-data» и «main» имеют совершенно разные истории.
archive/re
...
main
3
.gitattributes
поставляемый
Обычный файл
@ -0,0 +1,3 @@
|
||||
# correct the language detection on github
|
||||
# exclude data files from linguist analysis
|
||||
notebooks/* linguist-generated
|
||||
11
.github/dependabot.yml
поставляемый
Обычный файл
@ -0,0 +1,11 @@
|
||||
# To get started with Dependabot version updates, you'll need to specify which
|
||||
# package ecosystems to update and where the package manifests are located.
|
||||
# Please see the documentation for all configuration options:
|
||||
# https://docs.github.com/code-security/dependabot/dependabot-version-updates/configuration-options-for-the-dependabot.yml-file
|
||||
|
||||
version: 2
|
||||
updates:
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/" # Location of package manifests
|
||||
schedule:
|
||||
interval: "weekly"
|
||||
43
.github/workflows/ci.yml
поставляемый
Обычный файл
@ -0,0 +1,43 @@
|
||||
name: CI
|
||||
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ main ]
|
||||
pull_request:
|
||||
branches: [ main ]
|
||||
workflow_dispatch:
|
||||
|
||||
|
||||
jobs:
|
||||
test:
|
||||
runs-on: ${{ matrix.os }}
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
os: [ubuntu-latest, windows-latest, macos-latest]
|
||||
python-version: ['3.10', '3.11']
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install spacy --no-binary blis # do not compile blis from source
|
||||
pip install -e .[dev]
|
||||
- name: Run pytest
|
||||
run: |
|
||||
cd ammico
|
||||
python -m pytest -svv -m "not gcv" --cov=. --cov-report=xml
|
||||
- name: Upload coverage
|
||||
if: matrix.os == 'ubuntu-latest' && matrix.python-version == '3.11'
|
||||
uses: codecov/codecov-action@v3
|
||||
env:
|
||||
CODECOV_TOKEN: ${{ secrets.CODECOV_TOKEN }}
|
||||
with:
|
||||
fail_ci_if_error: false
|
||||
files: ammico/coverage.xml
|
||||
verbose: true
|
||||
36
.github/workflows/docs.yml
поставляемый
Обычный файл
@ -0,0 +1,36 @@
|
||||
name: Pages
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ main ]
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.11'
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0 # otherwise, you will failed to push refs to dest repo
|
||||
- name: install ammico
|
||||
run: |
|
||||
python -m pip install uv
|
||||
uv pip install --system -e .[dev]
|
||||
- name: set google auth
|
||||
uses: 'google-github-actions/auth@v0.4.0'
|
||||
with:
|
||||
credentials_json: '${{ secrets.GOOGLE_APPLICATION_CREDENTIALS }}'
|
||||
- name: get pandoc
|
||||
run: |
|
||||
sudo apt-get install -y pandoc
|
||||
- name: Build documentation
|
||||
run: |
|
||||
cd docs
|
||||
make html
|
||||
- name: Push changes to gh-pages
|
||||
uses: JamesIves/github-pages-deploy-action@v4
|
||||
with:
|
||||
folder: docs # The folder the action should deploy.
|
||||
77
.github/workflows/release.yml
поставляемый
Обычный файл
@ -0,0 +1,77 @@
|
||||
name: release to pypi
|
||||
|
||||
on:
|
||||
release:
|
||||
types: [published]
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
build:
|
||||
name: Build distribution
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
- name: Set up Python 3.11
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: "3.11"
|
||||
- name: install pypa/build
|
||||
run: >-
|
||||
python -m
|
||||
pip install
|
||||
build
|
||||
--user
|
||||
- name: Build distribution
|
||||
run: python -m build
|
||||
- name: store the dist packages
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: python-package-distributions
|
||||
path: dist/
|
||||
|
||||
publish-to-pypi:
|
||||
name: Publish to PyPI
|
||||
if: startsWith(github.ref, 'refs/tags/')
|
||||
needs:
|
||||
- build
|
||||
runs-on: ubuntu-latest
|
||||
environment:
|
||||
name: pypi
|
||||
url: https://pypi.org/p/ammico
|
||||
permissions:
|
||||
id-token: write
|
||||
steps:
|
||||
- name: Download all dists
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
name: python-package-distributions
|
||||
path: dist/
|
||||
- name: publish dist to pypi
|
||||
uses: pypa/gh-action-pypi-publish@release/v1
|
||||
|
||||
publish-to-testpypi:
|
||||
name: Publish Python distribution to TestPyPI
|
||||
if: startsWith(github.ref, 'refs/tags/')
|
||||
needs:
|
||||
- build
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
environment:
|
||||
name: testpypi
|
||||
url: https://test.pypi.org/p/ammico
|
||||
permissions:
|
||||
id-token: write # IMPORTANT: mandatory for trusted publishing
|
||||
|
||||
steps:
|
||||
- name: Download all the dists
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
name: python-package-distributions
|
||||
path: dist/
|
||||
- name: Publish distribution 📦 to TestPyPI
|
||||
uses: pypa/gh-action-pypi-publish@release/v1
|
||||
with:
|
||||
repository-url: https://test.pypi.org/legacy/
|
||||
|
||||
132
.gitignore
поставляемый
Обычный файл
@ -0,0 +1,132 @@
|
||||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*$py.class
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
# Distribution / packaging
|
||||
.Python
|
||||
build/
|
||||
develop-eggs/
|
||||
dist/
|
||||
downloads/
|
||||
eggs/
|
||||
.eggs/
|
||||
lib/
|
||||
lib64/
|
||||
parts/
|
||||
sdist/
|
||||
var/
|
||||
wheels/
|
||||
pip-wheel-metadata/
|
||||
share/python-wheels/
|
||||
*.egg-info/
|
||||
.installed.cfg
|
||||
*.egg
|
||||
MANIFEST
|
||||
|
||||
# PyInstaller
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
pip-delete-this-directory.txt
|
||||
|
||||
# Unit test / coverage reports
|
||||
htmlcov/
|
||||
.tox/
|
||||
.nox/
|
||||
.coverage
|
||||
.coverage.*
|
||||
.cache
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
*.cover
|
||||
*.py,cover
|
||||
.hypothesis/
|
||||
.pytest_cache/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
*.pot
|
||||
|
||||
# Django stuff:
|
||||
*.log
|
||||
local_settings.py
|
||||
db.sqlite3
|
||||
db.sqlite3-journal
|
||||
|
||||
# Flask stuff:
|
||||
instance/
|
||||
.webassets-cache
|
||||
|
||||
# Scrapy stuff:
|
||||
.scrapy
|
||||
|
||||
# Sphinx documentation
|
||||
docs/_build/
|
||||
|
||||
# PyBuilder
|
||||
target/
|
||||
|
||||
# Jupyter Notebook
|
||||
.ipynb_checkpoints
|
||||
|
||||
# IPython
|
||||
profile_default/
|
||||
ipython_config.py
|
||||
|
||||
# pyenv
|
||||
.python-version
|
||||
|
||||
# pipenv
|
||||
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
||||
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
||||
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
||||
# install all needed dependencies.
|
||||
#Pipfile.lock
|
||||
|
||||
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
||||
__pypackages__/
|
||||
|
||||
# Celery stuff
|
||||
celerybeat-schedule
|
||||
celerybeat.pid
|
||||
|
||||
# SageMath parsed files
|
||||
*.sage.py
|
||||
|
||||
# Environments
|
||||
.env
|
||||
.venv
|
||||
env/
|
||||
venv/
|
||||
ENV/
|
||||
env.bak/
|
||||
venv.bak/
|
||||
|
||||
# Spyder project settings
|
||||
.spyderproject
|
||||
.spyproject
|
||||
|
||||
# Rope project settings
|
||||
.ropeproject
|
||||
|
||||
# mkdocs documentation
|
||||
/site
|
||||
|
||||
# mypy
|
||||
.mypy_cache/
|
||||
.dmypy.json
|
||||
dmypy.json
|
||||
|
||||
# Pyre type checker
|
||||
.pyre/
|
||||
|
||||
# data folder
|
||||
/data/
|
||||
0
.gitmodules
поставляемый
Обычный файл
14
.pre-commit-config.yaml
Обычный файл
@ -0,0 +1,14 @@
|
||||
repos:
|
||||
- repo: https://github.com/kynan/nbstripout
|
||||
rev: 0.8.1
|
||||
hooks:
|
||||
- id: nbstripout
|
||||
files: ".ipynb"
|
||||
- repo: https://github.com/astral-sh/ruff-pre-commit
|
||||
# Ruff version.
|
||||
rev: v0.13.3
|
||||
hooks:
|
||||
# Run the linter.
|
||||
- id: ruff-check
|
||||
# Run the formatter.
|
||||
- id: ruff-format
|
||||
49
CITATION.cff
Обычный файл
@ -0,0 +1,49 @@
|
||||
cff-version: 1.2.0
|
||||
title: >-
|
||||
AMMICO, an AI-based Media and Misinformation Content
|
||||
Analysis Tool
|
||||
message: >-
|
||||
If you use this software, please cite it using the
|
||||
metadata from this file.
|
||||
type: software
|
||||
authors:
|
||||
- family-names: "Dumitrescu"
|
||||
given-names: "Delia"
|
||||
orcid: "https://orcid.org/0000-0002-0065-3875"
|
||||
- family-names: "Ulusoy"
|
||||
given-names: "Inga"
|
||||
orcid: "https://orcid.org/0000-0001-7294-4148"
|
||||
- family-names: "Andriushchenko"
|
||||
given-names: "Petr"
|
||||
orcid: "https://orcid.org/0000-0002-4518-6588"
|
||||
- family-names: "Daskalakis"
|
||||
given-names: "Gwydion"
|
||||
orcid: "https://orcid.org/0000-0002-7557-1364"
|
||||
- family-names: "Kempf"
|
||||
given-names: "Dominic"
|
||||
orcid: "https://orcid.org/0000-0002-6140-2332"
|
||||
- family-names: "Ma"
|
||||
given-names: "Xianghe"
|
||||
identifiers:
|
||||
- type: doi
|
||||
value: 10.5117/CCR2025.1.3.DUMI
|
||||
repository-code: 'https://github.com/ssciwr/AMMICO'
|
||||
url: 'https://ssciwr.github.io/AMMICO/build/html/index.html'
|
||||
abstract: >-
|
||||
ammico (AI-based Media and Misinformation Content Analysis
|
||||
Tool) is a publicly available software package written in
|
||||
Python 3, whose purpose is the simultaneous evaluation of
|
||||
the text and graphical content of image files. After
|
||||
describing the software features, we provide an assessment
|
||||
of its performance using a multi-country, multi-language
|
||||
data set containing COVID-19 social media disinformation
|
||||
posts. We conclude by highlighting the tool’s advantages
|
||||
for communication research.
|
||||
keywords:
|
||||
- nlp
|
||||
- translation
|
||||
- computer-vision
|
||||
- text-extraction
|
||||
- classification
|
||||
- social media
|
||||
license: MIT
|
||||
36
CONTRIBUTING.md
Обычный файл
@ -0,0 +1,36 @@
|
||||
# Contributing to ammico
|
||||
|
||||
Welcome to `ammico`! Contributions to the package are welcome. Please adhere to the following conventions:
|
||||
|
||||
- fork the repository, make your changes, and make sure your changes pass all the tests (Sonarcloud, unit and integration tests, codecoverage limits); then open a Pull Request for your changes. Tag one of `ammico`'s developers for review.
|
||||
- install and use the pre-commit hooks by running `pre-commit install` in the repository directory so that all your changes adhere to the PEP8 style guide and black code formatting
|
||||
- make sure to update the documentation if applicable
|
||||
|
||||
The tests are located in `ammico/tests`. Unit tests are named `test` following an underscore and the name of the module; inside the unit test modules, each test function is named `test` followed by an underscore and the name of the function/method that is being tested.
|
||||
|
||||
To report bugs and issues, please [open an issue](https://github.com/ssciwr/ammico/issues) describing what you did, what you expected to happen, and what actually happened. Please provide information about the environment as well as OS.
|
||||
|
||||
For any questions and comments, feel free to post to our [Discussions forum]((https://github.com/ssciwr/AMMICO/discussions/151)).
|
||||
|
||||
**Thank you for contributing to `ammico`!**
|
||||
|
||||
## Templates
|
||||
### Template for pull requests
|
||||
|
||||
- issues that are addressed by this PR: [*For example, this closes #33 or this addresses #29*]
|
||||
|
||||
- changes that were made: [*For example, updated version of dependencies or added a file type for input reading*]
|
||||
|
||||
- if applicable: Follow-up work that is required
|
||||
|
||||
### Template for bug report
|
||||
|
||||
- what I did:
|
||||
|
||||
- what I expected:
|
||||
|
||||
- what actually happened:
|
||||
|
||||
- Python version and environment:
|
||||
|
||||
- Operating system:
|
||||
23
Dockerfile
Обычный файл
@ -0,0 +1,23 @@
|
||||
FROM jupyter/base-notebook
|
||||
|
||||
# Install system dependencies for computer vision packages
|
||||
USER root
|
||||
RUN apt update && apt install -y build-essential libgl1 libglib2.0-0 libsm6 libxext6 libxrender1 \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
USER $NB_USER
|
||||
|
||||
# Copy the repository into the container
|
||||
COPY --chown=${NB_UID} . /opt/ammico
|
||||
|
||||
# Install the Python package
|
||||
RUN python -m pip install /opt/ammico
|
||||
|
||||
# Make JupyterLab the default for this application
|
||||
ENV JUPYTER_ENABLE_LAB=yes
|
||||
|
||||
# Export where the data is located
|
||||
ENV XDG_DATA_HOME=/opt/ammico/data
|
||||
|
||||
# Copy notebooks into the home directory
|
||||
RUN rm -rf "$HOME"/work && \
|
||||
cp /opt/ammico/notebooks/*.ipynb "$HOME"
|
||||
106
FAQ.md
Обычный файл
@ -0,0 +1,106 @@
|
||||
# FAQ
|
||||
|
||||
## Compatibility problems solving
|
||||
|
||||
Some ammico components require `tensorflow` (e.g. Emotion detector), some `pytorch` (e.g. Summary detector). Sometimes there are compatibility problems between these two frameworks. To avoid these problems on your machines, you can prepare proper environment before installing the package (you need conda on your machine):
|
||||
|
||||
### 1. First, install tensorflow (https://www.tensorflow.org/install/pip)
|
||||
- create a new environment with python and activate it
|
||||
|
||||
```conda create -n ammico_env python=3.10```
|
||||
|
||||
```conda activate ammico_env```
|
||||
- install cudatoolkit from conda-forge
|
||||
|
||||
``` conda install -c conda-forge cudatoolkit=11.8.0```
|
||||
- install nvidia-cudnn-cu11 from pip
|
||||
|
||||
```python -m pip install nvidia-cudnn-cu11==8.6.0.163```
|
||||
- add script that runs when conda environment `ammico_env` is activated to put the right libraries on your LD_LIBRARY_PATH
|
||||
|
||||
```
|
||||
mkdir -p $CONDA_PREFIX/etc/conda/activate.d
|
||||
echo 'CUDNN_PATH=$(dirname $(python -c "import nvidia.cudnn;print(nvidia.cudnn.__file__)"))' >> $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh
|
||||
echo 'export LD_LIBRARY_PATH=$CUDNN_PATH/lib:$CONDA_PREFIX/lib/:$LD_LIBRARY_PATH' >> $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh
|
||||
source $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh
|
||||
```
|
||||
- deactivate and re-activate conda environment to call script above
|
||||
|
||||
```conda deactivate```
|
||||
|
||||
```conda activate ammico_env ```
|
||||
|
||||
- install tensorflow
|
||||
|
||||
```python -m pip install tensorflow==2.12.1```
|
||||
|
||||
### 2. Second, install pytorch
|
||||
|
||||
- install pytorch for same cuda version as above
|
||||
|
||||
```python -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118```
|
||||
|
||||
### 3. After we prepared right environment we can install the ```ammico``` package
|
||||
|
||||
- ```python -m pip install ammico```
|
||||
|
||||
It is done.
|
||||
|
||||
### Micromamba
|
||||
If you are using micromamba you can prepare environment with just one command:
|
||||
|
||||
```micromamba create --no-channel-priority -c nvidia -c pytorch -c conda-forge -n ammico_env "python=3.10" pytorch torchvision torchaudio pytorch-cuda "tensorflow-gpu<=2.12.3" "numpy<=1.23.4"```
|
||||
|
||||
### Windows
|
||||
|
||||
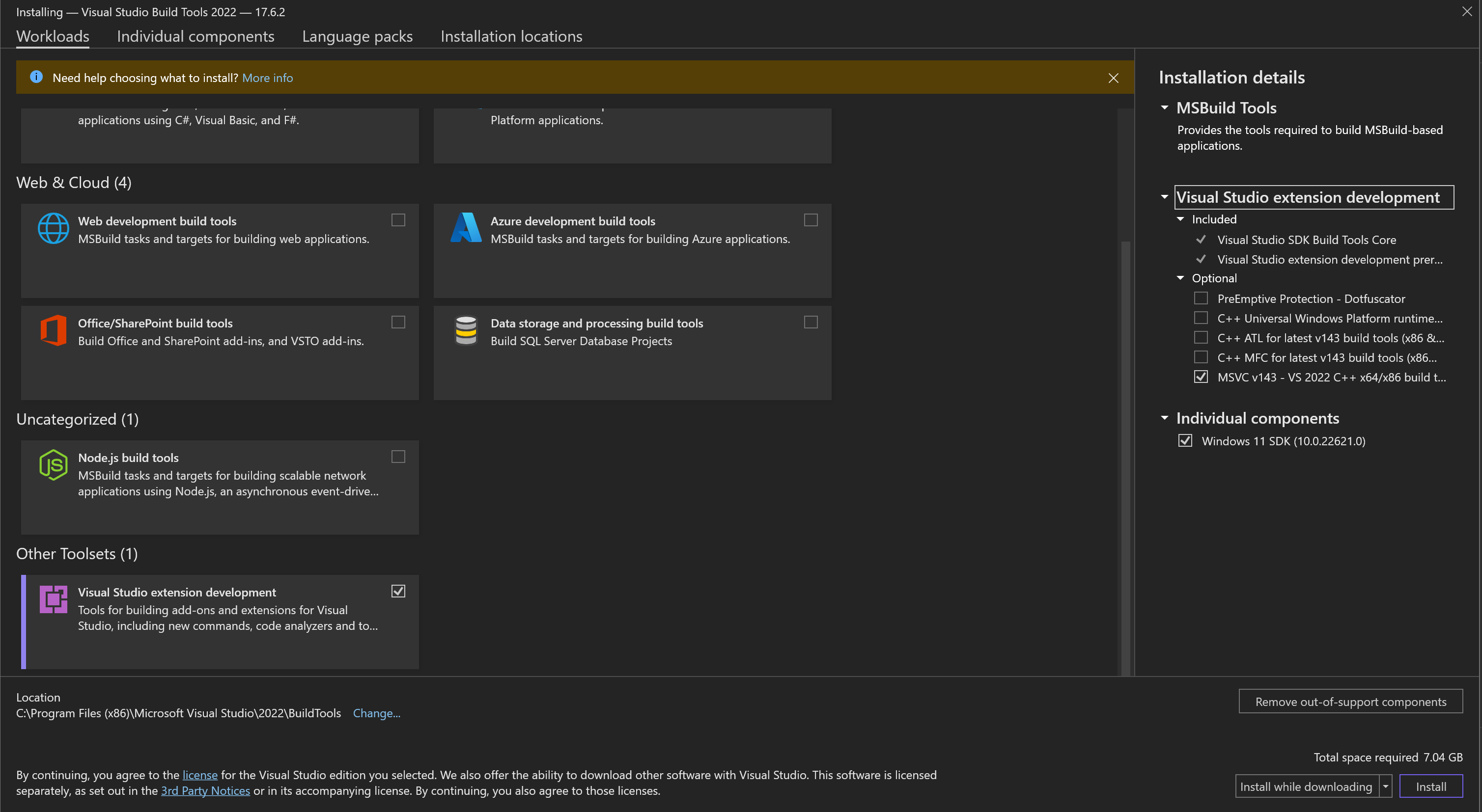
To make pycocotools work on Windows OS you may need to install `vs_BuildTools.exe` from https://visualstudio.microsoft.com/visual-cpp-build-tools/ and choose following elements:
|
||||
- `Visual Studio extension development`
|
||||
- `MSVC v143 - VS 2022 C++ x64/x86 build tools`
|
||||
- `Windows 11 SDK` for Windows 11 (or `Windows 10 SDK` for Windows 10)
|
||||
|
||||
Be careful, it requires around 7 GB of disk space.
|
||||
|
||||
|
||||
|
||||
## What happens to the images that are sent to google Cloud Vision?
|
||||
|
||||
You have to accept the privacy statement of ammico to run this type of analyis.
|
||||
|
||||
According to the [google Vision API](https://cloud.google.com/vision/docs/data-usage), the images that are uploaded and analysed are not stored and not shared with third parties:
|
||||
|
||||
> We won't make the content that you send available to the public. We won't share the content with any third party. The content is only used by Google as necessary to provide the Vision API service. Vision API complies with the Cloud Data Processing Addendum.
|
||||
|
||||
> For online (immediate response) operations (`BatchAnnotateImages` and `BatchAnnotateFiles`), the image data is processed in memory and not persisted to disk.
|
||||
For asynchronous offline batch operations (`AsyncBatchAnnotateImages` and `AsyncBatchAnnotateFiles`), we must store that image for a short period of time in order to perform the analysis and return the results to you. The stored image is typically deleted right after the processing is done, with a failsafe Time to live (TTL) of a few hours.
|
||||
Google also temporarily logs some metadata about your Vision API requests (such as the time the request was received and the size of the request) to improve our service and combat abuse.
|
||||
|
||||
## What happens to the text that is sent to google Translate?
|
||||
|
||||
You have to accept the privacy statement of ammico to run this type of analyis.
|
||||
|
||||
According to [google Translate](https://cloud.google.com/translate/data-usage), the data is not stored after processing and not made available to third parties:
|
||||
|
||||
> We will not make the content of the text that you send available to the public. We will not share the content with any third party. The content of the text is only used by Google as necessary to provide the Cloud Translation API service. Cloud Translation API complies with the Cloud Data Processing Addendum.
|
||||
|
||||
> When you send text to Cloud Translation API, text is held briefly in-memory in order to perform the translation and return the results to you.
|
||||
|
||||
## What happens if I don't have internet access - can I still use ammico?
|
||||
|
||||
Some features of ammico require internet access; a general answer to this question is not possible, some services require an internet connection, others can be used offline:
|
||||
|
||||
- Text extraction: To extract text from images, and translate the text, the data needs to be processed by google Cloud Vision and google Translate, which run in the cloud. Without internet access, text extraction and translation is not possible.
|
||||
- Image summary and query: After an initial download of the models, the `summary` module does not require an internet connection.
|
||||
- Facial expressions: After an initial download of the models, the `faces` module does not require an internet connection.
|
||||
- Multimodal search: After an initial download of the models, the `multimodal_search` module does not require an internet connection.
|
||||
- Color analysis: The `color` module does not require an internet connection.
|
||||
|
||||
## Why don't I get probabilistic assessments of age, gender and race when running the Emotion Detector?
|
||||
Due to well documented biases in the detection of minorities with computer vision tools, and to the ethical implications of such detection, these parts of the tool are not directly made available to users. To access these capabilities, users must first agree with a ethical disclosure statement that reads:
|
||||
|
||||
"DeepFace and RetinaFace provide wrappers to trained models in face recognition and emotion detection. Age, gender and race/ethnicity models were trained on the backbone of VGG-Face with transfer learning.
|
||||
|
||||
ETHICAL DISCLOSURE STATEMENT:
|
||||
|
||||
The Emotion Detector uses DeepFace and RetinaFace to probabilistically assess the gender, age and race of the detected faces. Such assessments may not reflect how the individuals identify. Additionally, the classification is carried out in simplistic categories and contains only the most basic classes (for example, “male” and “female” for gender, and seven non-overlapping categories for ethnicity). To access these probabilistic assessments, you must therefore agree with the following statement: “I understand the ethical and privacy implications such assessments have for the interpretation of the results and that this analysis may result in personal and possibly sensitive data, and I wish to proceed.”
|
||||
|
||||
This disclosure statement is included as a separate line of code early in the flow of the Emotion Detector. Once the user has agreed with the statement, further data analyses will also include these assessments.
|
||||
21
LICENSE
Обычный файл
@ -0,0 +1,21 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2022 SSC
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
84
README.md
Обычный файл
@ -0,0 +1,84 @@
|
||||
# AMMICO - AI-based Media and Misinformation Content Analysis Tool
|
||||
|
||||

|
||||

|
||||

|
||||

|
||||

|
||||
[](https://colab.research.google.com/github/ssciwr/ammico/blob/main/ammico/notebooks/DemoNotebook_ammico.ipynb)
|
||||
|
||||
This package extracts data from images such as social media posts that contain an image part and a text part. The analysis can generate a very large number of features, depending on the user input. See [our paper](https://dx.doi.org/10.31235/osf.io/v8txj) for a more in-depth description.
|
||||
|
||||
**_This project is currently under development!_**
|
||||
|
||||
Use pre-processed image files such as social media posts with comments and process to collect information:
|
||||
1. Text extraction from the images
|
||||
1. Language detection
|
||||
1. Translation into English or other languages
|
||||
1. Cleaning of the text, spell-check
|
||||
1. Sentiment analysis
|
||||
1. Named entity recognition
|
||||
1. Topic analysis
|
||||
1. Content extraction from the images
|
||||
1. Textual summary of the image content ("image caption") that can be analyzed further using the above tools
|
||||
1. Feature extraction from the images: User inputs query and images are matched to that query (both text and image query)
|
||||
1. Question answering
|
||||
1. Performing person and face recognition in images
|
||||
1. Face mask detection
|
||||
1. Probabilistic detection of age, gender and race
|
||||
1. Emotion recognition
|
||||
1. Color analysis
|
||||
1. Analyse hue and percentage of color on image
|
||||
1. Multimodal analysis
|
||||
1. Find best matches for image content or image similarity
|
||||
1. Cropping images to remove comments from posts
|
||||
|
||||
## Installation
|
||||
|
||||
The `AMMICO` package can be installed using pip:
|
||||
```
|
||||
pip install ammico
|
||||
```
|
||||
This will install the package and its dependencies locally. If after installation you get some errors when running some modules, please follow the instructions in the [FAQ](https://ssciwr.github.io/AMMICO/build/html/faq_link.html).
|
||||
|
||||
## Usage
|
||||
|
||||
The main demonstration notebook can be found in the `notebooks` folder and also on google colab: [](https://colab.research.google.com/github/ssciwr/ammico/blob/main/ammico/notebooks/DemoNotebook_ammico.ipynb)
|
||||
|
||||
There are further sample notebooks in the `notebooks` folder for the more experimental features:
|
||||
1. Topic analysis: Use the notebook `get-text-from-image.ipynb` to analyse the topics of the extraced text.\
|
||||
**You can run this notebook on google colab: [](https://colab.research.google.com/github/ssciwr/ammico/blob/main/ammico/notebooks/get-text-from-image.ipynb)**
|
||||
Place the data files and google cloud vision API key in your google drive to access the data.
|
||||
1. To crop social media posts use the `cropposts.ipynb` notebook.
|
||||
**You can run this notebook on google colab: [](https://colab.research.google.com/github/ssciwr/ammico/blob/main/ammico/notebooks/cropposts.ipynb)**
|
||||
|
||||
## Features
|
||||
### Text extraction
|
||||
The text is extracted from the images using [google-cloud-vision](https://cloud.google.com/vision). For this, you need an API key. Set up your google account following the instructions on the google Vision AI website or as described [here](https://ssciwr.github.io/AMMICO/build/html/create_API_key_link.html).
|
||||
You then need to export the location of the API key as an environment variable:
|
||||
```
|
||||
export GOOGLE_APPLICATION_CREDENTIALS="location of your .json"
|
||||
```
|
||||
The extracted text is then stored under the `text` key (column when exporting a csv).
|
||||
|
||||
[Googletrans](https://py-googletrans.readthedocs.io/en/latest/) is used to recognize the language automatically and translate into English. The text language and translated text is then stored under the `text_language` and `text_english` key (column when exporting a csv).
|
||||
|
||||
If you further want to analyse the text, you have to set the `analyse_text` keyword to `True`. In doing so, the text is then processed using [spacy](https://spacy.io/) (tokenized, part-of-speech, lemma, ...). The English text is cleaned from numbers and unrecognized words (`text_clean`), spelling of the English text is corrected (`text_english_correct`), and further sentiment and subjectivity analysis are carried out (`polarity`, `subjectivity`). The latter two steps are carried out using [TextBlob](https://textblob.readthedocs.io/en/dev/index.html). For more information on the sentiment analysis using TextBlob see [here](https://towardsdatascience.com/my-absolute-go-to-for-sentiment-analysis-textblob-3ac3a11d524).
|
||||
|
||||
The [Hugging Face transformers library](https://huggingface.co/) is used to perform another sentiment analysis, a text summary, and named entity recognition, using the `transformers` pipeline.
|
||||
|
||||
### Content extraction
|
||||
|
||||
The image content ("caption") is extracted using the [LAVIS](https://github.com/salesforce/LAVIS) library. This library enables vision intelligence extraction using several state-of-the-art models such as BLIP and BLIP2, depending on the task and user selection. Further, it allows feature extraction from the images, where users can input textual and image queries, and the images in the database are matched to that query (multimodal search). Another option is question answering, where the user inputs a text question and the library finds the images that match the query.
|
||||
|
||||
### Emotion recognition
|
||||
|
||||
Emotion recognition is carried out using the [deepface](https://github.com/serengil/deepface) and [retinaface](https://github.com/serengil/retinaface) libraries. These libraries detect the presence of faces, as well as provide probabilistic assessment of their age, gender, race, and emotion based on several state-of-the-art models. It is also detected if the person is wearing a face mask - if they are, then no further detection is carried out as the mask affects the assessment acuracy. Because the detection of gender, race and age is carried out in simplistic categories (e.g., for gender, using only "male" and "female"), and because of the ethical implications of such assessments, users can only access this part of the tool if they agree with an ethical disclosure statement (see FAQ). Moreover, once users accept the disclosure, they can further set their own detection confidence threshholds.
|
||||
|
||||
### Color/hue detection
|
||||
|
||||
Color detection is carried out using [colorgram.py](https://github.com/obskyr/colorgram.py) and [colour](https://github.com/vaab/colour) for the distance metric. The colors can be classified into the main named colors/hues in the English language, that are red, green, blue, yellow, cyan, orange, purple, pink, brown, grey, white, black.
|
||||
|
||||
### Cropping of posts
|
||||
|
||||
Social media posts can automatically be cropped to remove further comments on the page and restrict the textual content to the first comment only.
|
||||
23
ammico/__init__.py
Обычный файл
@ -0,0 +1,23 @@
|
||||
from ammico.display import AnalysisExplorer
|
||||
from ammico.faces import EmotionDetector, ethical_disclosure
|
||||
from ammico.text import TextDetector, TextAnalyzer, privacy_disclosure
|
||||
from ammico.utils import find_files, get_dataframe
|
||||
|
||||
# Export the version defined in project metadata
|
||||
try:
|
||||
from importlib.metadata import version
|
||||
|
||||
__version__ = version("ammico")
|
||||
except ImportError:
|
||||
__version__ = "unknown"
|
||||
|
||||
__all__ = [
|
||||
"AnalysisExplorer",
|
||||
"EmotionDetector",
|
||||
"TextDetector",
|
||||
"TextAnalyzer",
|
||||
"find_files",
|
||||
"get_dataframe",
|
||||
"ethical_disclosure",
|
||||
"privacy_disclosure",
|
||||
]
|
||||
145
ammico/colors.py
Обычный файл
@ -0,0 +1,145 @@
|
||||
import numpy as np
|
||||
import webcolors
|
||||
import colorgram
|
||||
import colour
|
||||
from ammico.utils import get_color_table, AnalysisMethod
|
||||
|
||||
COLOR_SCHEMES = [
|
||||
"CIE 1976",
|
||||
"CIE 1994",
|
||||
"CIE 2000",
|
||||
"CMC",
|
||||
"ITP",
|
||||
"CAM02-LCD",
|
||||
"CAM02-SCD",
|
||||
"CAM02-UCS",
|
||||
"CAM16-LCD",
|
||||
"CAM16-SCD",
|
||||
"CAM16-UCS",
|
||||
"DIN99",
|
||||
]
|
||||
|
||||
|
||||
class ColorDetector(AnalysisMethod):
|
||||
def __init__(
|
||||
self,
|
||||
subdict: dict,
|
||||
delta_e_method: str = "CIE 1976",
|
||||
) -> None:
|
||||
"""Color Analysis class, analyse hue and identify named colors.
|
||||
|
||||
Args:
|
||||
subdict (dict): The dictionary containing the image path.
|
||||
delta_e_method (str): The calculation method used for assigning the
|
||||
closest color name, defaults to "CIE 1976".
|
||||
The available options are: 'CIE 1976', 'CIE 1994', 'CIE 2000',
|
||||
'CMC', 'ITP', 'CAM02-LCD', 'CAM02-SCD', 'CAM02-UCS', 'CAM16-LCD',
|
||||
'CAM16-SCD', 'CAM16-UCS', 'DIN99'
|
||||
"""
|
||||
super().__init__(subdict)
|
||||
self.subdict.update(self.set_keys())
|
||||
self.merge_color = True
|
||||
self.n_colors = 100
|
||||
if delta_e_method not in COLOR_SCHEMES:
|
||||
raise ValueError(
|
||||
"Invalid selection for assigning the color name. Please select one of {}".format(
|
||||
COLOR_SCHEMES
|
||||
)
|
||||
)
|
||||
self.delta_e_method = delta_e_method
|
||||
|
||||
def set_keys(self) -> dict:
|
||||
colors = {
|
||||
"red": 0,
|
||||
"green": 0,
|
||||
"blue": 0,
|
||||
"yellow": 0,
|
||||
"cyan": 0,
|
||||
"orange": 0,
|
||||
"purple": 0,
|
||||
"pink": 0,
|
||||
"brown": 0,
|
||||
"grey": 0,
|
||||
"white": 0,
|
||||
"black": 0,
|
||||
}
|
||||
return colors
|
||||
|
||||
def analyse_image(self):
|
||||
"""
|
||||
Uses the colorgram library to extract the n most common colors from the images.
|
||||
One problem is, that the most common colors are taken before beeing categorized,
|
||||
so for small values it might occur that the ten most common colors are shades of grey,
|
||||
while other colors are present but will be ignored. Because of this n_colors=100 was chosen as default.
|
||||
|
||||
The colors are then matched to the closest color in the CSS3 color list using the delta-e metric.
|
||||
They are then merged into one data frame.
|
||||
The colors can be reduced to a smaller list of colors using the get_color_table function.
|
||||
These colors are: "red", "green", "blue", "yellow","cyan", "orange", "purple", "pink", "brown", "grey", "white", "black".
|
||||
|
||||
Returns:
|
||||
dict: Dictionary with color names as keys and percentage of color in image as values.
|
||||
"""
|
||||
filename = self.subdict["filename"]
|
||||
|
||||
colors = colorgram.extract(filename, self.n_colors)
|
||||
for color in colors:
|
||||
rgb_name = self.rgb2name(
|
||||
color.rgb,
|
||||
merge_color=self.merge_color,
|
||||
delta_e_method=self.delta_e_method,
|
||||
)
|
||||
self.subdict[rgb_name] += color.proportion
|
||||
|
||||
# ensure color rounding
|
||||
for key in self.set_keys().keys():
|
||||
if self.subdict[key]:
|
||||
self.subdict[key] = round(self.subdict[key], 2)
|
||||
|
||||
return self.subdict
|
||||
|
||||
def rgb2name(
|
||||
self, c, merge_color: bool = True, delta_e_method: str = "CIE 1976"
|
||||
) -> str:
|
||||
"""Take an rgb color as input and return the closest color name from the CSS3 color list.
|
||||
|
||||
Args:
|
||||
c (Union[List,tuple]): RGB value.
|
||||
merge_color (bool, Optional): Whether color name should be reduced, defaults to True.
|
||||
Returns:
|
||||
str: Closest matching color name.
|
||||
"""
|
||||
if len(c) != 3:
|
||||
raise ValueError("Input color must be a list or tuple of length 3 (RGB).")
|
||||
|
||||
h_color = "#{:02x}{:02x}{:02x}".format(int(c[0]), int(c[1]), int(c[2]))
|
||||
try:
|
||||
output_color = webcolors.hex_to_name(h_color, spec="css3")
|
||||
output_color = output_color.lower().replace("grey", "gray")
|
||||
except ValueError:
|
||||
delta_e_lst = []
|
||||
filtered_colors = webcolors._definitions._CSS3_NAMES_TO_HEX
|
||||
|
||||
for _, img_hex in filtered_colors.items():
|
||||
cur_clr = webcolors.hex_to_rgb(img_hex)
|
||||
# calculate color Delta-E
|
||||
delta_e = colour.delta_E(c, cur_clr, method=delta_e_method)
|
||||
delta_e_lst.append(delta_e)
|
||||
# find lowest delta-e
|
||||
min_diff = np.argsort(delta_e_lst)[0]
|
||||
output_color = (
|
||||
str(list(filtered_colors.items())[min_diff][0])
|
||||
.lower()
|
||||
.replace("grey", "gray")
|
||||
)
|
||||
|
||||
# match color to reduced list:
|
||||
if merge_color:
|
||||
for reduced_key, reduced_color_sub_list in get_color_table().items():
|
||||
if str(output_color).lower() in [
|
||||
str(color_name).lower()
|
||||
for color_name in reduced_color_sub_list["ColorName"]
|
||||
]:
|
||||
output_color = reduced_key.lower()
|
||||
break
|
||||
return output_color
|
||||
24
ammico/data/Color_tables.csv
Обычный файл
@ -0,0 +1,24 @@
|
||||
Pink;Pink;purple;purple;red;red;orange;orange;yellow;yellow;green;green;cyan;cyan;blue;blue;brown;brown;white;white;grey;grey;black;black
|
||||
ColorName;HEX;ColorName;HEX;ColorName;HEX;ColorName;HEX;ColorName;HEX;ColorName;HEX;ColorName;HEX;ColorName;HEX;ColorName;HEX;ColorName;HEX;ColorName;HEX;ColorName;HEX
|
||||
Pink;#FFC0CB;Lavender;#E6E6FA;LightSalmon;#FFA07A;Orange;#FFA500;Gold;#FFD700;GreenYellow;#ADFF2F;Aqua;#00FFFF;CadetBlue;#5F9EA0;Cornsilk;#FFF8DC;White;#FFFFFF;Gainsboro;#DCDCDC;Black;#000000
|
||||
LightPink;#FFB6C1;Thistle;#D8BFD8;Salmon;#FA8072;DarkOrange;#FF8C00;Yellow;#FFFF00;Chartreuse;#7FFF00;Cyan;#00FFFF;SteelBlue;#4682B4;BlanchedAlmond;#FFEBCD;Snow;#FFFAFA;LightGray;#D3D3D3;;
|
||||
HotPink;#FF69B4;Plum;#DDA0DD;DarkSalmon;#E9967A;Coral;#FF7F50;LightYellow;#FFFFE0;LawnGreen;#7CFC00;LightCyan;#E0FFFF;LightSteelBlue;#B0C4DE;Bisque;#FFE4C4;HoneyDew;#F0FFF0;Silver;#C0C0C0;;
|
||||
DeepPink;#FF1493;Orchid;#DA70D6;LightCoral;#F08080;Tomato;#FF6347;LemonChiffon;#FFFACD;Lime;#00FF00;PaleTurquoise;#AFEEEE;LightBlue;#ADD8E6;NavajoWhite;#FFDEAD;MintCream;#F5FFFA;DarkGray;#A9A9A9;;
|
||||
PaleVioletRed;#DB7093;Violet;#EE82EE;IndianRed;#CD5C5C;OrangeRed;#FF4500;LightGoldenRodYellow;#FAFAD2;LimeGreen;#32CD32;Aquamarine;#7FFFD4;PowderBlue;#B0E0E6;Wheat;#F5DEB3;Azure;#F0FFFF;DimGray;#696969;;
|
||||
MediumVioletRed;#C71585;Fuchsia;#FF00FF;Crimson;#DC143C;;;PapayaWhip;#FFEFD5;PaleGreen;#98FB98;Turquoise;#40E0D0;LightSkyBlue;#87CEFA;BurlyWood;#DEB887;AliceBlue;#F0F8FF;Gray;#808080;;
|
||||
;;Magenta;#FF00FF;Red;#FF0000;;;Moccasin;#FFE4B5;LightGreen;#90EE90;MediumTurquoise;#48D1CC;SkyBlue;#87CEEB;Tan;#D2B48C;GhostWhite;#F8F8FF;LightSlateGray;#778899;;
|
||||
;;MediumOrchid;#BA55D3;FireBrick;#B22222;;;PeachPuff;#FFDAB9;MediumSpringGreen;#00FA9A;DarkTurquoise;#00CED1;CornflowerBlue;#6495ED;RosyBrown;#BC8F8F;WhiteSmoke;#F5F5F5;SlateGray;#708090;;
|
||||
;;DarkOrchid;#9932CC;DarkRed;#8B0000;;;PaleGoldenRod;#EEE8AA;SpringGreen;#00FF7F;;;DeepSkyBlue;#00BFFF;SandyBrown;#F4A460;SeaShell;#FFF5EE;DarkSlateGray;#2F4F4F;;
|
||||
;;DarkViolet;#9400D3;;;;;Khaki;#F0E68C;MediumSeaGreen;#3CB371;;;DodgerBlue;#1E90FF;GoldenRod;#DAA520;Beige;#F5F5DC;;;;
|
||||
;;BlueViolet;#8A2BE2;;;;;DarkKhaki;#BDB76B;SeaGreen;#2E8B57;;;RoyalBlue;#4169E1;DarkGoldenRod;#B8860B;OldLace;#FDF5E6;;;;
|
||||
;;DarkMagenta;#8B008B;;;;;;;ForestGreen;#228B22;;;Blue;#0000FF;Peru;#CD853F;FloralWhite;#FFFAF0;;;;
|
||||
;;Purple;#800080;;;;;;;Green;#008000;;;MediumBlue;#0000CD;Chocolate;#D2691E;Ivory;#FFFFF0;;;;
|
||||
;;MediumPurple;#9370DB;;;;;;;DarkGreen;#006400;;;DarkBlue;#00008B;Olive;#808000;AntiqueWhite;#FAEBD7;;;;
|
||||
;;MediumSlateBlue;#7B68EE;;;;;;;YellowGreen;#9ACD32;;;Navy;#000080;SaddleBrown;#8B4513;Linen;#FAF0E6;;;;
|
||||
;;SlateBlue;#6A5ACD;;;;;;;OliveDrab;#6B8E23;;;MidnightBlue;#191970;Sienna;#A0522D;LavenderBlush;#FFF0F5;;;;
|
||||
;;DarkSlateBlue;#483D8B;;;;;;;DarkOliveGreen;#556B2F;;;;;Brown;#A52A2A;MistyRose;#FFE4E1;;;;
|
||||
;;RebeccaPurple;#663399;;;;;;;MediumAquaMarine;#66CDAA;;;;;Maroon;#800000;;;;;;
|
||||
;;Indigo;#4B0082;;;;;;;DarkSeaGreen;#8FBC8F;;;;;;;;;;;;
|
||||
;;;;;;;;;;LightSeaGreen;#20B2AA;;;;;;;;;;;;
|
||||
;;;;;;;;;;DarkCyan;#008B8B;;;;;;;;;;;;
|
||||
;;;;;;;;;;Teal;#008080;;;;;;;;;;;;
|
||||
|
482
ammico/display.py
Обычный файл
@ -0,0 +1,482 @@
|
||||
import ammico.faces as faces
|
||||
import ammico.text as text
|
||||
import ammico.colors as colors
|
||||
import pandas as pd
|
||||
from dash import html, Input, Output, dcc, State, Dash
|
||||
from PIL import Image
|
||||
import dash_bootstrap_components as dbc
|
||||
|
||||
|
||||
COLOR_SCHEMES = [
|
||||
"CIE 1976",
|
||||
"CIE 1994",
|
||||
"CIE 2000",
|
||||
"CMC",
|
||||
"ITP",
|
||||
"CAM02-LCD",
|
||||
"CAM02-SCD",
|
||||
"CAM02-UCS",
|
||||
"CAM16-LCD",
|
||||
"CAM16-SCD",
|
||||
"CAM16-UCS",
|
||||
"DIN99",
|
||||
]
|
||||
SUMMARY_ANALYSIS_TYPE = ["summary_and_questions", "summary", "questions"]
|
||||
SUMMARY_MODEL = ["base", "large"]
|
||||
|
||||
|
||||
class AnalysisExplorer:
|
||||
def __init__(self, mydict: dict) -> None:
|
||||
"""Initialize the AnalysisExplorer class to create an interactive
|
||||
visualization of the analysis results.
|
||||
|
||||
Args:
|
||||
mydict (dict): A nested dictionary containing image data for all images.
|
||||
|
||||
"""
|
||||
self.app = Dash(__name__, external_stylesheets=[dbc.themes.BOOTSTRAP])
|
||||
self.mydict = mydict
|
||||
self.theme = {
|
||||
"scheme": "monokai",
|
||||
"author": "wimer hazenberg (http://www.monokai.nl)",
|
||||
"base00": "#272822",
|
||||
"base01": "#383830",
|
||||
"base02": "#49483e",
|
||||
"base03": "#75715e",
|
||||
"base04": "#a59f85",
|
||||
"base05": "#f8f8f2",
|
||||
"base06": "#f5f4f1",
|
||||
"base07": "#f9f8f5",
|
||||
"base08": "#f92672",
|
||||
"base09": "#fd971f",
|
||||
"base0A": "#f4bf75",
|
||||
"base0B": "#a6e22e",
|
||||
"base0C": "#a1efe4",
|
||||
"base0D": "#66d9ef",
|
||||
"base0E": "#ae81ff",
|
||||
"base0F": "#cc6633",
|
||||
}
|
||||
|
||||
# Setup the layout
|
||||
app_layout = html.Div(
|
||||
[
|
||||
# Top row, only file explorer
|
||||
dbc.Row(
|
||||
[dbc.Col(self._top_file_explorer(mydict))],
|
||||
id="Div_top",
|
||||
style={
|
||||
"width": "30%",
|
||||
},
|
||||
),
|
||||
# second row, middle picture and right output
|
||||
dbc.Row(
|
||||
[
|
||||
# first column: picture
|
||||
dbc.Col(self._middle_picture_frame()),
|
||||
dbc.Col(self._right_output_json()),
|
||||
]
|
||||
),
|
||||
],
|
||||
# style={"width": "95%", "display": "inline-block"},
|
||||
)
|
||||
self.app.layout = app_layout
|
||||
|
||||
# Add callbacks to the app
|
||||
self.app.callback(
|
||||
Output("img_middle_picture_id", "src"),
|
||||
Input("left_select_id", "value"),
|
||||
prevent_initial_call=True,
|
||||
)(self.update_picture)
|
||||
|
||||
self.app.callback(
|
||||
Output("right_json_viewer", "children"),
|
||||
Input("button_run", "n_clicks"),
|
||||
State("left_select_id", "options"),
|
||||
State("left_select_id", "value"),
|
||||
State("Dropdown_select_Detector", "value"),
|
||||
State("setting_Text_analyse_text", "value"),
|
||||
State("setting_privacy_env_var", "value"),
|
||||
State("setting_Emotion_emotion_threshold", "value"),
|
||||
State("setting_Emotion_race_threshold", "value"),
|
||||
State("setting_Emotion_gender_threshold", "value"),
|
||||
State("setting_Emotion_env_var", "value"),
|
||||
State("setting_Color_delta_e_method", "value"),
|
||||
prevent_initial_call=True,
|
||||
)(self._right_output_analysis)
|
||||
|
||||
self.app.callback(
|
||||
Output("settings_TextDetector", "style"),
|
||||
Output("settings_EmotionDetector", "style"),
|
||||
Output("settings_ColorDetector", "style"),
|
||||
Input("Dropdown_select_Detector", "value"),
|
||||
)(self._update_detector_setting)
|
||||
|
||||
# I split the different sections into subfunctions for better clarity
|
||||
def _top_file_explorer(self, mydict: dict) -> html.Div:
|
||||
"""Initialize the file explorer dropdown for selecting the file to be analyzed.
|
||||
|
||||
Args:
|
||||
mydict (dict): A dictionary containing image data.
|
||||
|
||||
Returns:
|
||||
html.Div: The layout for the file explorer dropdown.
|
||||
"""
|
||||
left_layout = html.Div(
|
||||
[
|
||||
dcc.Dropdown(
|
||||
options={value["filename"]: key for key, value in mydict.items()},
|
||||
id="left_select_id",
|
||||
)
|
||||
]
|
||||
)
|
||||
return left_layout
|
||||
|
||||
def _middle_picture_frame(self) -> html.Div:
|
||||
"""Initialize the picture frame to display the image.
|
||||
|
||||
Returns:
|
||||
html.Div: The layout for the picture frame.
|
||||
"""
|
||||
middle_layout = html.Div(
|
||||
[
|
||||
html.Img(
|
||||
id="img_middle_picture_id",
|
||||
style={
|
||||
"width": "80%",
|
||||
},
|
||||
)
|
||||
]
|
||||
)
|
||||
return middle_layout
|
||||
|
||||
def _create_setting_layout(self):
|
||||
settings_layout = html.Div(
|
||||
[
|
||||
# text summary start
|
||||
html.Div(
|
||||
id="settings_TextDetector",
|
||||
style={"display": "none"},
|
||||
children=[
|
||||
dbc.Row(
|
||||
dcc.Checklist(
|
||||
["Analyse text"],
|
||||
["Analyse text"],
|
||||
id="setting_Text_analyse_text",
|
||||
style={"margin-bottom": "10px"},
|
||||
),
|
||||
),
|
||||
# row 1
|
||||
dbc.Row(
|
||||
dbc.Col(
|
||||
[
|
||||
html.P(
|
||||
"Privacy disclosure acceptance environment variable"
|
||||
),
|
||||
dcc.Input(
|
||||
type="text",
|
||||
value="PRIVACY_AMMICO",
|
||||
id="setting_privacy_env_var",
|
||||
style={"width": "100%"},
|
||||
),
|
||||
],
|
||||
align="start",
|
||||
),
|
||||
),
|
||||
],
|
||||
), # text summary end
|
||||
# start emotion detector
|
||||
html.Div(
|
||||
id="settings_EmotionDetector",
|
||||
style={"display": "none"},
|
||||
children=[
|
||||
dbc.Row(
|
||||
[
|
||||
dbc.Col(
|
||||
[
|
||||
html.P("Emotion threshold"),
|
||||
dcc.Input(
|
||||
value=50,
|
||||
type="number",
|
||||
max=100,
|
||||
min=0,
|
||||
id="setting_Emotion_emotion_threshold",
|
||||
style={"width": "100%"},
|
||||
),
|
||||
],
|
||||
align="start",
|
||||
),
|
||||
dbc.Col(
|
||||
[
|
||||
html.P("Race threshold"),
|
||||
dcc.Input(
|
||||
type="number",
|
||||
value=50,
|
||||
max=100,
|
||||
min=0,
|
||||
id="setting_Emotion_race_threshold",
|
||||
style={"width": "100%"},
|
||||
),
|
||||
],
|
||||
align="start",
|
||||
),
|
||||
dbc.Col(
|
||||
[
|
||||
html.P("Gender threshold"),
|
||||
dcc.Input(
|
||||
type="number",
|
||||
value=50,
|
||||
max=100,
|
||||
min=0,
|
||||
id="setting_Emotion_gender_threshold",
|
||||
style={"width": "100%"},
|
||||
),
|
||||
],
|
||||
align="start",
|
||||
),
|
||||
dbc.Col(
|
||||
[
|
||||
html.P(
|
||||
"Disclosure acceptance environment variable"
|
||||
),
|
||||
dcc.Input(
|
||||
type="text",
|
||||
value="DISCLOSURE_AMMICO",
|
||||
id="setting_Emotion_env_var",
|
||||
style={"width": "100%"},
|
||||
),
|
||||
],
|
||||
align="start",
|
||||
),
|
||||
],
|
||||
style={"width": "100%"},
|
||||
),
|
||||
],
|
||||
), # end emotion detector
|
||||
html.Div(
|
||||
id="settings_ColorDetector",
|
||||
style={"display": "none"},
|
||||
children=[
|
||||
html.Div(
|
||||
[
|
||||
dcc.Dropdown(
|
||||
options=COLOR_SCHEMES,
|
||||
value="CIE 1976",
|
||||
id="setting_Color_delta_e_method",
|
||||
)
|
||||
],
|
||||
style={
|
||||
"width": "49%",
|
||||
"display": "inline-block",
|
||||
"margin-top": "10px",
|
||||
},
|
||||
)
|
||||
],
|
||||
),
|
||||
],
|
||||
style={"width": "100%", "display": "inline-block"},
|
||||
)
|
||||
return settings_layout
|
||||
|
||||
def _right_output_json(self) -> html.Div:
|
||||
"""Initialize the DetectorDropdown, argument Div and JSON viewer for displaying the analysis output.
|
||||
|
||||
Returns:
|
||||
html.Div: The layout for the JSON viewer.
|
||||
"""
|
||||
right_layout = html.Div(
|
||||
[
|
||||
dbc.Col(
|
||||
[
|
||||
dbc.Row(
|
||||
dcc.Dropdown(
|
||||
options=[
|
||||
"TextDetector",
|
||||
"EmotionDetector",
|
||||
"ColorDetector",
|
||||
],
|
||||
value="TextDetector",
|
||||
id="Dropdown_select_Detector",
|
||||
style={"width": "60%"},
|
||||
),
|
||||
justify="start",
|
||||
),
|
||||
dbc.Row(
|
||||
children=[self._create_setting_layout()],
|
||||
id="div_detector_args",
|
||||
justify="start",
|
||||
),
|
||||
dbc.Row(
|
||||
html.Button(
|
||||
"Run Detector",
|
||||
id="button_run",
|
||||
style={
|
||||
"margin-top": "15px",
|
||||
"margin-bottom": "15px",
|
||||
"margin-left": "11px",
|
||||
"width": "30%",
|
||||
},
|
||||
),
|
||||
justify="start",
|
||||
),
|
||||
dbc.Row(
|
||||
dcc.Loading(
|
||||
id="loading-2",
|
||||
children=[
|
||||
# This is where the json is shown.
|
||||
html.Div(id="right_json_viewer"),
|
||||
],
|
||||
type="circle",
|
||||
),
|
||||
justify="start",
|
||||
),
|
||||
],
|
||||
align="start",
|
||||
)
|
||||
]
|
||||
)
|
||||
return right_layout
|
||||
|
||||
def run_server(self, port: int = 8050) -> None:
|
||||
"""Run the Dash server to start the analysis explorer.
|
||||
|
||||
|
||||
Args:
|
||||
port (int, optional): The port number to run the server on (default: 8050).
|
||||
"""
|
||||
|
||||
self.app.run_server(debug=True, port=port)
|
||||
|
||||
# Dash callbacks
|
||||
def update_picture(self, img_path: str):
|
||||
"""Callback function to update the displayed image.
|
||||
|
||||
Args:
|
||||
img_path (str): The path of the selected image.
|
||||
|
||||
Returns:
|
||||
Union[PIL.PngImagePlugin, None]: The image object to be displayed
|
||||
or None if the image path is
|
||||
|
||||
"""
|
||||
if img_path is not None:
|
||||
image = Image.open(img_path)
|
||||
return image
|
||||
else:
|
||||
return None
|
||||
|
||||
def _update_detector_setting(self, setting_input):
|
||||
# return settings_TextDetector -> style, settings_EmotionDetector -> style
|
||||
display_none = {"display": "none"}
|
||||
display_flex = {
|
||||
"display": "flex",
|
||||
"flexWrap": "wrap",
|
||||
"width": 400,
|
||||
"margin-top": "20px",
|
||||
}
|
||||
|
||||
if setting_input == "TextDetector":
|
||||
return display_flex, display_none, display_none, display_none
|
||||
|
||||
if setting_input == "EmotionDetector":
|
||||
return display_none, display_flex, display_none, display_none
|
||||
|
||||
if setting_input == "ColorDetector":
|
||||
return display_none, display_none, display_flex, display_none
|
||||
|
||||
else:
|
||||
return display_none, display_none, display_none, display_none
|
||||
|
||||
def _right_output_analysis(
|
||||
self,
|
||||
n_clicks,
|
||||
all_img_options: dict,
|
||||
current_img_value: str,
|
||||
detector_value: str,
|
||||
settings_text_analyse_text: list,
|
||||
setting_privacy_env_var: str,
|
||||
setting_emotion_emotion_threshold: int,
|
||||
setting_emotion_race_threshold: int,
|
||||
setting_emotion_gender_threshold: int,
|
||||
setting_emotion_env_var: str,
|
||||
setting_color_delta_e_method: str,
|
||||
) -> dict:
|
||||
"""Callback function to perform analysis on the selected image and return the output.
|
||||
|
||||
Args:
|
||||
all_options (dict): The available options in the file explorer dropdown.
|
||||
current_value (str): The current selected value in the file explorer dropdown.
|
||||
|
||||
Returns:
|
||||
dict: The analysis output for the selected image.
|
||||
"""
|
||||
identify_dict = {
|
||||
"EmotionDetector": faces.EmotionDetector,
|
||||
"TextDetector": text.TextDetector,
|
||||
"ColorDetector": colors.ColorDetector,
|
||||
}
|
||||
|
||||
# Get image ID from dropdown value, which is the filepath
|
||||
if current_img_value is None:
|
||||
return {}
|
||||
image_id = all_img_options[current_img_value]
|
||||
# copy image so prvious runs don't leave their default values in the dict
|
||||
image_copy = self.mydict[image_id].copy()
|
||||
|
||||
# detector value is the string name of the chosen detector
|
||||
identify_function = identify_dict[detector_value]
|
||||
|
||||
if detector_value == "TextDetector":
|
||||
analyse_text = (
|
||||
True if settings_text_analyse_text == ["Analyse text"] else False
|
||||
)
|
||||
detector_class = identify_function(
|
||||
image_copy,
|
||||
analyse_text=analyse_text,
|
||||
accept_privacy=(
|
||||
setting_privacy_env_var
|
||||
if setting_privacy_env_var
|
||||
else "PRIVACY_AMMICO"
|
||||
),
|
||||
)
|
||||
elif detector_value == "EmotionDetector":
|
||||
detector_class = identify_function(
|
||||
image_copy,
|
||||
emotion_threshold=setting_emotion_emotion_threshold,
|
||||
race_threshold=setting_emotion_race_threshold,
|
||||
gender_threshold=setting_emotion_gender_threshold,
|
||||
accept_disclosure=(
|
||||
setting_emotion_env_var
|
||||
if setting_emotion_env_var
|
||||
else "DISCLOSURE_AMMICO"
|
||||
),
|
||||
)
|
||||
elif detector_value == "ColorDetector":
|
||||
detector_class = identify_function(
|
||||
image_copy,
|
||||
delta_e_method=setting_color_delta_e_method,
|
||||
)
|
||||
else:
|
||||
detector_class = identify_function(image_copy)
|
||||
analysis_dict = detector_class.analyse_image()
|
||||
|
||||
# Initialize an empty dictionary
|
||||
new_analysis_dict = {}
|
||||
|
||||
# Iterate over the items in the original dictionary
|
||||
for k, v in analysis_dict.items():
|
||||
# Check if the value is a list
|
||||
if isinstance(v, list):
|
||||
# If it is, convert each item in the list to a string and join them with a comma
|
||||
new_value = ", ".join([str(f) for f in v])
|
||||
else:
|
||||
# If it's not a list, keep the value as it is
|
||||
new_value = v
|
||||
|
||||
# Add the new key-value pair to the new dictionary
|
||||
new_analysis_dict[k] = new_value
|
||||
|
||||
df = pd.DataFrame([new_analysis_dict]).set_index("filename").T
|
||||
df.index.rename("filename", inplace=True)
|
||||
return dbc.Table.from_dataframe(
|
||||
df, striped=True, bordered=True, hover=True, index=True
|
||||
)
|
||||
405
ammico/faces.py
Обычный файл
@ -0,0 +1,405 @@
|
||||
import cv2
|
||||
import numpy as np
|
||||
import os
|
||||
import shutil
|
||||
import pathlib
|
||||
from tensorflow.keras.models import load_model
|
||||
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
|
||||
from tensorflow.keras.preprocessing.image import img_to_array
|
||||
import keras.backend as K
|
||||
from deepface import DeepFace
|
||||
from retinaface import RetinaFace
|
||||
from ammico.utils import DownloadResource, AnalysisMethod
|
||||
|
||||
|
||||
DEEPFACE_PATH = ".deepface"
|
||||
# alternative solution to the memory leaks
|
||||
# cfg = K.tf.compat.v1.ConfigProto()
|
||||
# cfg.gpu_options.allow_growth = True
|
||||
# K.set_session(K.tf.compat.v1.Session(config=cfg))
|
||||
|
||||
|
||||
def deepface_symlink_processor(name):
|
||||
def _processor(fname, action, pooch):
|
||||
if not os.path.exists(name):
|
||||
# symlink does not work on windows
|
||||
# use copy if running on windows
|
||||
if os.name != "nt":
|
||||
os.symlink(fname, name)
|
||||
else:
|
||||
shutil.copy(fname, name)
|
||||
return fname
|
||||
|
||||
return _processor
|
||||
|
||||
|
||||
face_mask_model = DownloadResource(
|
||||
url="https://github.com/chandrikadeb7/Face-Mask-Detection/raw/v1.0.0/mask_detector.model",
|
||||
known_hash="sha256:d0b30e2c7f8f187c143d655dee8697fcfbe8678889565670cd7314fb064eadc8",
|
||||
)
|
||||
|
||||
deepface_age_model = DownloadResource(
|
||||
url="https://github.com/serengil/deepface_models/releases/download/v1.0/age_model_weights.h5",
|
||||
known_hash="sha256:0aeff75734bfe794113756d2bfd0ac823d51e9422c8961125b570871d3c2b114",
|
||||
processor=deepface_symlink_processor(
|
||||
pathlib.Path.home().joinpath(DEEPFACE_PATH, "weights", "age_model_weights.h5")
|
||||
),
|
||||
)
|
||||
|
||||
deepface_face_expression_model = DownloadResource(
|
||||
url="https://github.com/serengil/deepface_models/releases/download/v1.0/facial_expression_model_weights.h5",
|
||||
known_hash="sha256:e8e8851d3fa05c001b1c27fd8841dfe08d7f82bb786a53ad8776725b7a1e824c",
|
||||
processor=deepface_symlink_processor(
|
||||
pathlib.Path.home().joinpath(
|
||||
".deepface", "weights", "facial_expression_model_weights.h5"
|
||||
)
|
||||
),
|
||||
)
|
||||
|
||||
deepface_gender_model = DownloadResource(
|
||||
url="https://github.com/serengil/deepface_models/releases/download/v1.0/gender_model_weights.h5",
|
||||
known_hash="sha256:45513ce5678549112d25ab85b1926fb65986507d49c674a3d04b2ba70dba2eb5",
|
||||
processor=deepface_symlink_processor(
|
||||
pathlib.Path.home().joinpath(
|
||||
DEEPFACE_PATH, "weights", "gender_model_weights.h5"
|
||||
)
|
||||
),
|
||||
)
|
||||
|
||||
deepface_race_model = DownloadResource(
|
||||
url="https://github.com/serengil/deepface_models/releases/download/v1.0/race_model_single_batch.h5",
|
||||
known_hash="sha256:eb22b28b1f6dfce65b64040af4e86003a5edccb169a1a338470dde270b6f5e54",
|
||||
processor=deepface_symlink_processor(
|
||||
pathlib.Path.home().joinpath(
|
||||
DEEPFACE_PATH, "weights", "race_model_single_batch.h5"
|
||||
)
|
||||
),
|
||||
)
|
||||
|
||||
retinaface_model = DownloadResource(
|
||||
url="https://github.com/serengil/deepface_models/releases/download/v1.0/retinaface.h5",
|
||||
known_hash="sha256:ecb2393a89da3dd3d6796ad86660e298f62a0c8ae7578d92eb6af14e0bb93adf",
|
||||
processor=deepface_symlink_processor(
|
||||
pathlib.Path.home().joinpath(DEEPFACE_PATH, "weights", "retinaface.h5")
|
||||
),
|
||||
)
|
||||
|
||||
ETHICAL_STATEMENT = """DeepFace and RetinaFace provide wrappers to trained models in face
|
||||
recognition and emotion detection. Age, gender and race/ethnicity models were trained on
|
||||
the backbone of VGG-Face with transfer learning.
|
||||
|
||||
ETHICAL DISCLOSURE STATEMENT:
|
||||
The Emotion Detector uses DeepFace and RetinaFace to probabilistically assess the gender,
|
||||
age and race of the detected faces. Such assessments may not reflect how the individuals
|
||||
identify. Additionally, the classification is carried out in simplistic categories and
|
||||
contains only the most basic classes (for example, "male" and "female" for gender, and seven
|
||||
non-overlapping categories for ethnicity). To access these probabilistic assessments, you
|
||||
must therefore agree with the following statement: "I understand the ethical and privacy
|
||||
implications such assessments have for the interpretation of the results and that this
|
||||
analysis may result in personal and possibly sensitive data, and I wish to proceed."
|
||||
Please type your answer in the adjacent box: "YES" for "I agree with the statement" or "NO"
|
||||
for "I disagree with the statement."
|
||||
"""
|
||||
|
||||
|
||||
def ethical_disclosure(accept_disclosure: str = "DISCLOSURE_AMMICO"):
|
||||
"""
|
||||
Asks the user to accept the ethical disclosure.
|
||||
|
||||
Args:
|
||||
accept_disclosure (str): The name of the disclosure variable (default: "DISCLOSURE_AMMICO").
|
||||
"""
|
||||
if not os.environ.get(accept_disclosure):
|
||||
accepted = _ask_for_disclosure_acceptance(accept_disclosure)
|
||||
elif os.environ.get(accept_disclosure) == "False":
|
||||
accepted = False
|
||||
elif os.environ.get(accept_disclosure) == "True":
|
||||
accepted = True
|
||||
else:
|
||||
print(
|
||||
"Could not determine disclosure - skipping \
|
||||
race/ethnicity, gender and age detection."
|
||||
)
|
||||
accepted = False
|
||||
return accepted
|
||||
|
||||
|
||||
def _ask_for_disclosure_acceptance(accept_disclosure: str = "DISCLOSURE_AMMICO"):
|
||||
"""
|
||||
Asks the user to accept the disclosure.
|
||||
"""
|
||||
print(ETHICAL_STATEMENT)
|
||||
answer = input("Do you accept the disclosure? (yes/no): ")
|
||||
answer = answer.lower().strip()
|
||||
if answer == "yes":
|
||||
print("You have accepted the disclosure.")
|
||||
print(
|
||||
"""Age, gender, race/ethnicity detection will be performed based on the provided
|
||||
confidence thresholds."""
|
||||
)
|
||||
os.environ[accept_disclosure] = "True"
|
||||
accepted = True
|
||||
elif answer == "no":
|
||||
print("You have not accepted the disclosure.")
|
||||
print("No age, gender, race/ethnicity detection will be performed.")
|
||||
os.environ[accept_disclosure] = "False"
|
||||
accepted = False
|
||||
else:
|
||||
print("Please answer with yes or no.")
|
||||
accepted = _ask_for_disclosure_acceptance()
|
||||
return accepted
|
||||
|
||||
|
||||
class EmotionDetector(AnalysisMethod):
|
||||
def __init__(
|
||||
self,
|
||||
subdict: dict,
|
||||
emotion_threshold: float = 50.0,
|
||||
race_threshold: float = 50.0,
|
||||
gender_threshold: float = 50.0,
|
||||
accept_disclosure: str = "DISCLOSURE_AMMICO",
|
||||
) -> None:
|
||||
"""
|
||||
Initializes the EmotionDetector object.
|
||||
|
||||
Args:
|
||||
subdict (dict): The dictionary to store the analysis results.
|
||||
emotion_threshold (float): The threshold for detecting emotions (default: 50.0).
|
||||
race_threshold (float): The threshold for detecting race (default: 50.0).
|
||||
gender_threshold (float): The threshold for detecting gender (default: 50.0).
|
||||
accept_disclosure (str): The name of the disclosure variable, that is
|
||||
set upon accepting the disclosure (default: "DISCLOSURE_AMMICO").
|
||||
"""
|
||||
super().__init__(subdict)
|
||||
self.subdict.update(self.set_keys())
|
||||
# check if thresholds are valid
|
||||
if emotion_threshold < 0 or emotion_threshold > 100:
|
||||
raise ValueError("Emotion threshold must be between 0 and 100.")
|
||||
if race_threshold < 0 or race_threshold > 100:
|
||||
raise ValueError("Race threshold must be between 0 and 100.")
|
||||
if gender_threshold < 0 or gender_threshold > 100:
|
||||
raise ValueError("Gender threshold must be between 0 and 100.")
|
||||
self.emotion_threshold = emotion_threshold
|
||||
self.race_threshold = race_threshold
|
||||
self.gender_threshold = gender_threshold
|
||||
self.emotion_categories = {
|
||||
"angry": "Negative",
|
||||
"disgust": "Negative",
|
||||
"fear": "Negative",
|
||||
"sad": "Negative",
|
||||
"happy": "Positive",
|
||||
"surprise": "Neutral",
|
||||
"neutral": "Neutral",
|
||||
}
|
||||
self.accepted = ethical_disclosure(accept_disclosure)
|
||||
|
||||
def set_keys(self) -> dict:
|
||||
"""
|
||||
Sets the initial parameters for the analysis.
|
||||
|
||||
Returns:
|
||||
dict: The dictionary with initial parameter values.
|
||||
"""
|
||||
params = {
|
||||
"face": "No",
|
||||
"multiple_faces": "No",
|
||||
"no_faces": 0,
|
||||
"wears_mask": ["No"],
|
||||
}
|
||||
return params
|
||||
|
||||
def analyse_image(self) -> dict:
|
||||
"""
|
||||
Performs facial expression analysis on the image.
|
||||
|
||||
Returns:
|
||||
dict: The updated subdict dictionary with analysis results.
|
||||
"""
|
||||
return self.facial_expression_analysis()
|
||||
|
||||
def _define_actions(self, fresult: dict) -> list:
|
||||
# Adapt the features we are looking for depending on whether a mask is worn.
|
||||
# White masks screw race detection, emotion detection is useless.
|
||||
# also, depending on the disclosure, we might not want to run the analysis
|
||||
# for gender, age, ethnicity/race
|
||||
conditional_actions = {
|
||||
"all": ["age", "gender", "race", "emotion"],
|
||||
"all_with_mask": ["age"],
|
||||
"restricted_access": ["emotion"],
|
||||
"restricted_access_with_mask": [],
|
||||
}
|
||||
if fresult["wears_mask"] and self.accepted:
|
||||
self.actions = conditional_actions["all_with_mask"]
|
||||
elif fresult["wears_mask"] and not self.accepted:
|
||||
self.actions = conditional_actions["restricted_access_with_mask"]
|
||||
elif not fresult["wears_mask"] and self.accepted:
|
||||
self.actions = conditional_actions["all"]
|
||||
elif not fresult["wears_mask"] and not self.accepted:
|
||||
self.actions = conditional_actions["restricted_access"]
|
||||
else:
|
||||
raise ValueError(
|
||||
"Invalid mask detection {} and disclosure \
|
||||
acceptance {} result.".format(
|
||||
fresult["wears_mask"], self.accepted
|
||||
)
|
||||
)
|
||||
|
||||
def _ensure_deepface_models(self):
|
||||
# Ensure that all data has been fetched by pooch
|
||||
if "emotion" in self.actions:
|
||||
deepface_face_expression_model.get()
|
||||
if "race" in self.actions:
|
||||
deepface_race_model.get()
|
||||
if "age" in self.actions:
|
||||
deepface_age_model.get()
|
||||
if "gender" in self.actions:
|
||||
deepface_gender_model.get()
|
||||
|
||||
def analyze_single_face(self, face: np.ndarray) -> dict:
|
||||
"""
|
||||
Analyzes the features of a single face on the image.
|
||||
|
||||
Args:
|
||||
face (np.ndarray): The face image array.
|
||||
|
||||
Returns:
|
||||
dict: The analysis results for the face.
|
||||
"""
|
||||
fresult = {}
|
||||
# Determine whether the face wears a mask
|
||||
fresult["wears_mask"] = self.wears_mask(face)
|
||||
self._define_actions(fresult)
|
||||
self._ensure_deepface_models()
|
||||
# Run the full DeepFace analysis
|
||||
# this returns a list of dictionaries
|
||||
# one dictionary per face that is detected in the image
|
||||
# since we are only passing a subregion of the image
|
||||
# that contains one face, the list will only contain one dict
|
||||
print("actions are:", self.actions)
|
||||
if self.actions != []:
|
||||
fresult["result"] = DeepFace.analyze(
|
||||
img_path=face,
|
||||
actions=self.actions,
|
||||
silent=True,
|
||||
)
|
||||
return fresult
|
||||
|
||||
def facial_expression_analysis(self) -> dict:
|
||||
"""
|
||||
Performs facial expression analysis on the image.
|
||||
|
||||
Returns:
|
||||
dict: The updated subdict dictionary with analysis results.
|
||||
"""
|
||||
# Find (multiple) faces in the image and cut them
|
||||
retinaface_model.get()
|
||||
|
||||
faces = RetinaFace.extract_faces(self.subdict["filename"])
|
||||
# If no faces are found, we return empty keys
|
||||
if len(faces) == 0:
|
||||
return self.subdict
|
||||
# Sort the faces by sight to prioritize prominent faces
|
||||
faces = list(reversed(sorted(faces, key=lambda f: f.shape[0] * f.shape[1])))
|
||||
self.subdict["face"] = "Yes"
|
||||
self.subdict["multiple_faces"] = "Yes" if len(faces) > 1 else "No"
|
||||
# number of faces only counted up to 15, after that set to 99
|
||||
self.subdict["no_faces"] = len(faces) if len(faces) <= 15 else 99
|
||||
# note number of faces being identified
|
||||
# We limit ourselves to identify emotion on max three faces per image
|
||||
result = {"number_faces": len(faces) if len(faces) <= 3 else 3}
|
||||
for i, face in enumerate(faces[:3]):
|
||||
result[f"person{i + 1}"] = self.analyze_single_face(face)
|
||||
self.clean_subdict(result)
|
||||
# release memory
|
||||
K.clear_session()
|
||||
return self.subdict
|
||||
|
||||
def clean_subdict(self, result: dict) -> dict:
|
||||
"""
|
||||
Cleans the subdict dictionary by converting results into appropriate formats.
|
||||
|
||||
Args:
|
||||
result (dict): The analysis results.
|
||||
Returns:
|
||||
dict: The updated subdict dictionary.
|
||||
"""
|
||||
# Each person subdict converted into list for keys
|
||||
self.subdict["wears_mask"] = []
|
||||
if "emotion" in self.actions:
|
||||
self.subdict["emotion (category)"] = []
|
||||
for key in self.actions:
|
||||
self.subdict[key] = []
|
||||
# now iterate over the number of faces
|
||||
# and check thresholds
|
||||
# the results for each person are returned as a nested dict
|
||||
# race and emotion are given as dict with confidence values
|
||||
# gender and age are given as one value with no confidence
|
||||
# being passed
|
||||
for i in range(result["number_faces"]):
|
||||
person = "person{}".format(i + 1)
|
||||
wears_mask = result[person]["wears_mask"]
|
||||
self.subdict["wears_mask"].append("Yes" if wears_mask else "No")
|
||||
# actually the actions dict should take care of
|
||||
# the person wearing a mask or not
|
||||
for key in self.actions:
|
||||
resultdict = result[person]["result"][0]
|
||||
if key == "emotion":
|
||||
classified_emotion = resultdict["dominant_emotion"]
|
||||
confidence_value = resultdict[key][classified_emotion]
|
||||
outcome = (
|
||||
classified_emotion
|
||||
if confidence_value > self.emotion_threshold and not wears_mask
|
||||
else None
|
||||
)
|
||||
print("emotion confidence", confidence_value, outcome)
|
||||
# also set the emotion category
|
||||
if outcome:
|
||||
self.subdict["emotion (category)"].append(
|
||||
self.emotion_categories[outcome]
|
||||
)
|
||||
else:
|
||||
self.subdict["emotion (category)"].append(None)
|
||||
elif key == "race":
|
||||
classified_race = resultdict["dominant_race"]
|
||||
confidence_value = resultdict[key][classified_race]
|
||||
outcome = (
|
||||
classified_race
|
||||
if confidence_value > self.race_threshold and not wears_mask
|
||||
else None
|
||||
)
|
||||
elif key == "age":
|
||||
outcome = resultdict[key]
|
||||
elif key == "gender":
|
||||
classified_gender = resultdict["dominant_gender"]
|
||||
confidence_value = resultdict[key][classified_gender]
|
||||
outcome = (
|
||||
classified_gender
|
||||
if confidence_value > self.gender_threshold and not wears_mask
|
||||
else None
|
||||
)
|
||||
self.subdict[key].append(outcome)
|
||||
return self.subdict
|
||||
|
||||
def wears_mask(self, face: np.ndarray) -> bool:
|
||||
"""
|
||||
Determines whether a face wears a mask.
|
||||
|
||||
Args:
|
||||
face (np.ndarray): The face image array.
|
||||
|
||||
Returns:
|
||||
bool: True if the face wears a mask, False otherwise.
|
||||
"""
|
||||
global mask_detection_model
|
||||
# Preprocess the face to match the assumptions of the face mask detection model
|
||||
face = cv2.cvtColor(face, cv2.COLOR_BGR2RGB)
|
||||
face = cv2.resize(face, (224, 224))
|
||||
face = img_to_array(face)
|
||||
face = preprocess_input(face)
|
||||
face = np.expand_dims(face, axis=0)
|
||||
# Lazily load the model
|
||||
mask_detection_model = load_model(face_mask_model.get())
|
||||
# Run the model
|
||||
mask, without_mask = mask_detection_model.predict(face)[0]
|
||||
# Convert from np.bool_ to bool to later be able to serialize the result
|
||||
return bool(mask > without_mask)
|
||||
1567
ammico/notebooks/DemoNotebook_ammico.ipynb
Обычный файл
48
ammico/test/conftest.py
Обычный файл
@ -0,0 +1,48 @@
|
||||
import os
|
||||
import pytest
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def get_path(request):
|
||||
mypath = os.path.dirname(request.module.__file__)
|
||||
mypath = mypath + "/data/"
|
||||
return mypath
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def set_environ(request):
|
||||
mypath = os.path.dirname(request.module.__file__)
|
||||
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = (
|
||||
mypath + "/../../data/seismic-bonfire-329406-412821a70264.json"
|
||||
)
|
||||
print(os.environ.get("GOOGLE_APPLICATION_CREDENTIALS"))
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def get_testdict(get_path):
|
||||
testdict = {
|
||||
"IMG_2746": {"filename": get_path + "IMG_2746.png"},
|
||||
"IMG_2809": {"filename": get_path + "IMG_2809.png"},
|
||||
}
|
||||
return testdict
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def get_test_my_dict(get_path):
|
||||
test_my_dict = {
|
||||
"IMG_2746": {
|
||||
"filename": get_path + "IMG_2746.png",
|
||||
"rank A bus": 1,
|
||||
"A bus": 0.15640679001808167,
|
||||
"rank " + get_path + "IMG_3758.png": 1,
|
||||
get_path + "IMG_3758.png": 0.7533495426177979,
|
||||
},
|
||||
"IMG_2809": {
|
||||
"filename": get_path + "IMG_2809.png",
|
||||
"rank A bus": 0,
|
||||
"A bus": 0.1970970332622528,
|
||||
"rank " + get_path + "IMG_3758.png": 0,
|
||||
get_path + "IMG_3758.png": 0.8907483816146851,
|
||||
},
|
||||
}
|
||||
return test_my_dict
|
||||
Двоичные данные
ammico/test/data/IMG_2746.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 1005 KiB |
Двоичные данные
ammico/test/data/IMG_2809.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 1.2 MiB |
Двоичные данные
ammico/test/data/IMG_3755.jpg
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 58 KiB |
Двоичные данные
ammico/test/data/IMG_3756.jpg
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 48 KiB |
Двоичные данные
ammico/test/data/IMG_3757.jpg
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 42 KiB |
Двоичные данные
ammico/test/data/IMG_3758.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 307 KiB |
37
ammico/test/data/example_append_data_to_dict_in.json
Обычный файл
@ -0,0 +1,37 @@
|
||||
{"image01":
|
||||
{
|
||||
"filename": "./data/image01.jpg",
|
||||
"person": "yes",
|
||||
"bicycle": "no",
|
||||
"car": "no",
|
||||
"motorcycle": "no",
|
||||
"airplane": "no",
|
||||
"bus": "no",
|
||||
"train": "no",
|
||||
"truck": "no",
|
||||
"boat": "no",
|
||||
"traffic light": "no",
|
||||
"cell phone": "yes",
|
||||
"gender": "male",
|
||||
"wears_mask": "no",
|
||||
"race": "asian"
|
||||
},
|
||||
"image02":
|
||||
{
|
||||
"filename": "./data/image02.jpg",
|
||||
"person": "no",
|
||||
"bicycle": "no",
|
||||
"car": "yes",
|
||||
"motorcycle": "no",
|
||||
"airplane": "no",
|
||||
"bus": "yes",
|
||||
"train": "no",
|
||||
"truck": "yes",
|
||||
"boat": "no",
|
||||
"traffic light": "yes",
|
||||
"cell phone": "no",
|
||||
"gender": "male",
|
||||
"wears_mask": "no",
|
||||
"race": "asian"
|
||||
}
|
||||
}
|
||||
17
ammico/test/data/example_append_data_to_dict_out.json
Обычный файл
@ -0,0 +1,17 @@
|
||||
{
|
||||
"filename": ["./data/image01.jpg", "./data/image02.jpg"],
|
||||
"person": ["yes", "no"],
|
||||
"bicycle": ["no", "no"],
|
||||
"car": ["no", "yes"],
|
||||
"motorcycle": ["no", "no"],
|
||||
"airplane": ["no", "no"],
|
||||
"bus": ["no", "yes"],
|
||||
"train": ["no", "no"],
|
||||
"truck": ["no", "yes"],
|
||||
"boat": ["no", "no"],
|
||||
"traffic light": ["no", "yes"],
|
||||
"cell phone": ["yes", "no"],
|
||||
"gender": ["male", "male"],
|
||||
"wears_mask": ["no", "no"],
|
||||
"race": ["asian", "asian"]
|
||||
}
|
||||
3
ammico/test/data/example_dump_df.csv
Обычный файл
@ -0,0 +1,3 @@
|
||||
,filename,person,bicycle,car,motorcycle,airplane,bus,train,truck,boat,traffic light,cell phone,gender,wears_mask,race
|
||||
0,./data/image01.jpg,yes,no,no,no,no,no,no,no,no,no,yes,male,no,asian
|
||||
1,./data/image02.jpg,no,no,yes,no,no,yes,no,yes,no,yes,no,male,no,asian
|
||||
|
33
ammico/test/data/example_faces.json
Обычный файл
@ -0,0 +1,33 @@
|
||||
{
|
||||
"pexels-pixabay-415829":
|
||||
{
|
||||
"face": "Yes",
|
||||
"multiple_faces": "No",
|
||||
"no_faces": 1,
|
||||
"wears_mask": ["No"],
|
||||
"gender": ["Woman"],
|
||||
"race": ["asian"],
|
||||
"emotion": ["happy"],
|
||||
"emotion (category)": ["Positive"]
|
||||
},
|
||||
"pexels-1000990-1954659":
|
||||
{
|
||||
"face": "Yes",
|
||||
"multiple_faces": "Yes",
|
||||
"no_faces": 2,
|
||||
"wears_mask": ["No", "No"],
|
||||
"gender": ["Man", "Man"],
|
||||
"race": ["asian", "white"],
|
||||
"emotion": [null, null],
|
||||
"emotion (category)": [null, null]
|
||||
},
|
||||
"pexels-maksgelatin-4750169":
|
||||
{
|
||||
"face": "Yes",
|
||||
"multiple_faces": "No",
|
||||
"no_faces": 1,
|
||||
"wears_mask": ["Yes"]
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
6
ammico/test/data/example_utils_init_dict.json
Обычный файл
@ -0,0 +1,6 @@
|
||||
{
|
||||
"image_faces": {
|
||||
"filename": "./test/data/image_faces.jpg"},
|
||||
"image_objects":
|
||||
{"filename": "./test/data/image_objects.jpg"}
|
||||
}
|
||||
Двоичные данные
ammico/test/data/pexels-1000990-1954659.jpg
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 1.7 MiB |
Двоичные данные
ammico/test/data/pexels-maksgelatin-4750169.jpg
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 1.3 MiB |
Двоичные данные
ammico/test/data/pexels-pixabay-415829.jpg
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 1.2 MiB |
Двоичные данные
ammico/test/data/test-utf16.csv
Обычный файл
|
8
ammico/test/data/test.csv
Обычный файл
@ -0,0 +1,8 @@
|
||||
text, date
|
||||
this is a test, 05/31/24
|
||||
bu bir denemedir, 05/31/24
|
||||
dies ist ein Test, 05/31/24
|
||||
c'est un test, 05/31/24
|
||||
esto es una prueba, 05/31/24
|
||||
detta är ett test, 05/31/24
|
||||
|
||||
|
52
ammico/test/data/test_data_out.csv
Обычный файл
@ -0,0 +1,52 @@
|
||||
,filename,text,text_language,text_english
|
||||
0,./test/data/IMG_3755.jpg,,,"Mathematische Formelsammlung
|
||||
für Ingenieure und Naturwissenschaftler
|
||||
Mit zahlreichen Abbildungen und Rechenbeispielen
|
||||
und einer ausführlichen Integraltafel
|
||||
3., verbesserte Auflage"
|
||||
1,./test/data/IMG_3756.jpg,"SCATTERING THEORY
|
||||
The Quantum Theory of
|
||||
Nonrelativistic Collisions
|
||||
JOHN R. TAYLOR
|
||||
University of Colorado
|
||||
ostaliga Lanbidean
|
||||
1 ilde
|
||||
ballenger stor goin
|
||||
gdĐOL, SIVI 23 TL 02
|
||||
de in obl
|
||||
och yd badalang
|
||||
a
|
||||
Ber
|
||||
ook Sy-RW enot go baldus",om,"SCATTERING THEORY
|
||||
The Quantum Theory of
|
||||
Nonrelativistic Collisions
|
||||
JOHN R. TAYLOR
|
||||
University of Colorado
|
||||
ostaliga Lanbidean
|
||||
1 ilde
|
||||
balloons big goin
|
||||
gdĐOL, SIVI 23 TL
|
||||
there in obl
|
||||
och yd change
|
||||
a
|
||||
Ber
|
||||
ook Sy-RW isn't going anywhere"
|
||||
2,./test/data/IMG_3757.jpg,"THE
|
||||
ALGEBRAIC
|
||||
EIGENVALUE
|
||||
PROBLEM
|
||||
DOM
|
||||
NVS TIO
|
||||
MINA
|
||||
Monographs
|
||||
on Numerical Analysis
|
||||
J.. H. WILKINSON",en,"THE
|
||||
ALGEBRAIC
|
||||
EIGENVALUE
|
||||
PROBLEM
|
||||
DOM
|
||||
NVS TIO
|
||||
MINA
|
||||
Monographs
|
||||
on Numerical Analysis
|
||||
J.. H. WILKINSON"
|
||||
|
52
ammico/test/data/test_data_out_nokey.csv
Обычный файл
@ -0,0 +1,52 @@
|
||||
,filename,text,text_language,text_nglish
|
||||
0,./test/data/IMG_3755.jpg,,,"Mathematische Formelsammlung
|
||||
für Ingenieure und Naturwissenschaftler
|
||||
Mit zahlreichen Abbildungen und Rechenbeispielen
|
||||
und einer ausführlichen Integraltafel
|
||||
3., verbesserte Auflage"
|
||||
1,./test/data/IMG_3756.jpg,"SCATTERING THEORY
|
||||
The Quantum Theory of
|
||||
Nonrelativistic Collisions
|
||||
JOHN R. TAYLOR
|
||||
University of Colorado
|
||||
ostaliga Lanbidean
|
||||
1 ilde
|
||||
ballenger stor goin
|
||||
gdĐOL, SIVI 23 TL 02
|
||||
de in obl
|
||||
och yd badalang
|
||||
a
|
||||
Ber
|
||||
ook Sy-RW enot go baldus",om,"SCATTERING THEORY
|
||||
The Quantum Theory of
|
||||
Nonrelativistic Collisions
|
||||
JOHN R. TAYLOR
|
||||
University of Colorado
|
||||
ostaliga Lanbidean
|
||||
1 ilde
|
||||
balloons big goin
|
||||
gdĐOL, SIVI 23 TL
|
||||
there in obl
|
||||
och yd change
|
||||
a
|
||||
Ber
|
||||
ook Sy-RW isn't going anywhere"
|
||||
2,./test/data/IMG_3757.jpg,"THE
|
||||
ALGEBRAIC
|
||||
EIGENVALUE
|
||||
PROBLEM
|
||||
DOM
|
||||
NVS TIO
|
||||
MINA
|
||||
Monographs
|
||||
on Numerical Analysis
|
||||
J.. H. WILKINSON",en,"THE
|
||||
ALGEBRAIC
|
||||
EIGENVALUE
|
||||
PROBLEM
|
||||
DOM
|
||||
NVS TIO
|
||||
MINA
|
||||
Monographs
|
||||
on Numerical Analysis
|
||||
J.. H. WILKINSON"
|
||||
|
32
ammico/test/data/test_read_csv_ref.json
Обычный файл
@ -0,0 +1,32 @@
|
||||
{
|
||||
"test.csvrow-1":
|
||||
{
|
||||
"filename": "test.csv",
|
||||
"text": "this is a test"
|
||||
},
|
||||
"test.csvrow-2":
|
||||
{
|
||||
"filename": "test.csv",
|
||||
"text": "bu bir denemedir"
|
||||
},
|
||||
"test.csvrow-3":
|
||||
{
|
||||
"filename": "test.csv",
|
||||
"text": "dies ist ein Test"
|
||||
},
|
||||
"test.csvrow-4":
|
||||
{
|
||||
"filename": "test.csv",
|
||||
"text": "c'est un test"
|
||||
},
|
||||
"test.csvrow-5":
|
||||
{
|
||||
"filename": "test.csv",
|
||||
"text": "esto es una prueba"
|
||||
},
|
||||
"test.csvrow-6":
|
||||
{
|
||||
"filename": "test.csv",
|
||||
"text": "detta är ett test"
|
||||
}
|
||||
}
|
||||
5
ammico/test/data/text_IMG_3755.txt
Обычный файл
@ -0,0 +1,5 @@
|
||||
Mathematische Formelsammlung
|
||||
für Ingenieure und Naturwissenschaftler
|
||||
Mit zahlreichen Abbildungen und Rechenbeispielen
|
||||
und einer ausführlichen Integraltafel
|
||||
3., verbesserte Auflage
|
||||
5
ammico/test/data/text_IMG_3756.txt
Обычный файл
@ -0,0 +1,5 @@
|
||||
SCATTERING THEORY
|
||||
The Quantum Theory of
|
||||
Nonrelativistic Collisions
|
||||
JOHN R. TAYLOR
|
||||
University of Colorado
|
||||
1
ammico/test/data/text_IMG_3757.txt
Обычный файл
@ -0,0 +1 @@
|
||||
THE ALGEBRAIC EIGENVALUE PROBLEM
|
||||
1
ammico/test/data/text_translated_IMG_3755.txt
Обычный файл
@ -0,0 +1 @@
|
||||
mathematical formula engineers scientists
|
||||
1
ammico/test/data/text_translated_IMG_3756.txt
Обычный файл
@ -0,0 +1 @@
|
||||
scattering theory quantum nonrelativistic university
|
||||
1
ammico/test/data/text_translated_IMG_3757.txt
Обычный файл
@ -0,0 +1 @@
|
||||
the algebraic eigenvalue problem
|
||||
5
ammico/test/pytest.ini
Обычный файл
@ -0,0 +1,5 @@
|
||||
[pytest]
|
||||
markers =
|
||||
gcv: mark google cloud vision tests - skip to save money.
|
||||
long: mark long running tests - skip to save compute resources.
|
||||
win_skip: mark tests that are skipped on windows.
|
||||
77
ammico/test/test_colors.py
Обычный файл
@ -0,0 +1,77 @@
|
||||
from ammico.colors import ColorDetector
|
||||
import pytest
|
||||
from numpy import isclose
|
||||
|
||||
|
||||
def test_init():
|
||||
delta_e_method = "CIE 1976"
|
||||
cd = ColorDetector({})
|
||||
assert cd.delta_e_method == delta_e_method
|
||||
delta_e_method = "CIE 1994"
|
||||
cd = ColorDetector({}, delta_e_method)
|
||||
assert cd.delta_e_method == delta_e_method
|
||||
delta_e_method = "nonsense"
|
||||
with pytest.raises(ValueError):
|
||||
ColorDetector({}, delta_e_method)
|
||||
|
||||
|
||||
def test_set_keys():
|
||||
colors = {
|
||||
"red": 0,
|
||||
"green": 0,
|
||||
"blue": 0,
|
||||
"yellow": 0,
|
||||
"cyan": 0,
|
||||
"orange": 0,
|
||||
"purple": 0,
|
||||
"pink": 0,
|
||||
"brown": 0,
|
||||
"grey": 0,
|
||||
"white": 0,
|
||||
"black": 0,
|
||||
}
|
||||
cd = ColorDetector({})
|
||||
|
||||
for color_key, value in colors.items():
|
||||
assert cd.subdict[color_key] == value
|
||||
|
||||
|
||||
def test_rgb2name(get_path):
|
||||
cd = ColorDetector({})
|
||||
|
||||
assert cd.rgb2name([0, 0, 0]) == "black"
|
||||
assert cd.rgb2name([255, 255, 255]) == "white"
|
||||
assert cd.rgb2name([205, 133, 63]) == "brown"
|
||||
|
||||
assert cd.rgb2name([255, 255, 255], merge_color=False) == "white"
|
||||
assert cd.rgb2name([0, 0, 0], merge_color=False) == "black"
|
||||
assert cd.rgb2name([205, 133, 63], merge_color=False) == "peru"
|
||||
|
||||
with pytest.raises(ValueError):
|
||||
cd.rgb2name([1, 2])
|
||||
|
||||
with pytest.raises(ValueError):
|
||||
cd.rgb2name([1, 2, 3, 4])
|
||||
|
||||
|
||||
def test_analyze_images(get_path):
|
||||
mydict_1 = {
|
||||
"filename": get_path + "IMG_2809.png",
|
||||
}
|
||||
mydict_2 = {
|
||||
"filename": get_path + "IMG_2809.png",
|
||||
}
|
||||
|
||||
test1 = ColorDetector(mydict_1, delta_e_method="CIE 2000").analyse_image()
|
||||
assert isclose(test1["red"], 0.0, atol=0.01)
|
||||
assert isclose(test1["green"], 0.63, atol=0.01)
|
||||
|
||||
test2 = ColorDetector(mydict_2).analyse_image()
|
||||
assert isclose(test2["red"], 0.0, atol=0.01)
|
||||
assert isclose(test2["green"], 0.06, atol=0.01)
|
||||
|
||||
mydict_1["test"] = "test"
|
||||
test3 = ColorDetector(mydict_1).analyse_image()
|
||||
assert isclose(test3["red"], 0.0, atol=0.01)
|
||||
assert isclose(test3["green"], 0.06, atol=0.01)
|
||||
assert test3["test"] == "test"
|
||||
60
ammico/test/test_display.py
Обычный файл
@ -0,0 +1,60 @@
|
||||
import json
|
||||
import ammico.display as ammico_display
|
||||
import pytest
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def get_options(get_path):
|
||||
path_img_1 = get_path + "IMG_2809.png"
|
||||
path_img_2 = get_path + "IMG_2746.png"
|
||||
|
||||
mydict = {
|
||||
"IMG_2809": {"filename": path_img_1},
|
||||
"IMG_2746": {"filename": path_img_2},
|
||||
}
|
||||
|
||||
all_options_dict = {
|
||||
path_img_1: "IMG_2809",
|
||||
path_img_2: "IMG_2746",
|
||||
}
|
||||
return path_img_1, path_img_2, mydict, all_options_dict
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def get_AE(get_options):
|
||||
analysis_explorer = ammico_display.AnalysisExplorer(get_options[2])
|
||||
return analysis_explorer
|
||||
|
||||
|
||||
def test_explore_analysis_faces(get_path):
|
||||
mydict = {"IMG_2746": {"filename": get_path + "IMG_2746.png"}}
|
||||
with open(get_path + "example_faces.json", "r") as file:
|
||||
outs = json.load(file)
|
||||
mydict["IMG_2746"].pop("filename", None)
|
||||
for im_key in mydict.keys():
|
||||
sub_dict = mydict[im_key]
|
||||
for key in sub_dict.keys():
|
||||
assert sub_dict[key] == outs[key]
|
||||
|
||||
|
||||
def test_AnalysisExplorer(get_AE, get_options):
|
||||
get_AE.update_picture(get_options[0])
|
||||
assert get_AE.update_picture(None) is None
|
||||
|
||||
|
||||
def test_right_output_analysis_emotions(get_AE, get_options, monkeypatch):
|
||||
monkeypatch.setenv("SOME_VAR", "True")
|
||||
monkeypatch.setenv("OTHER_VAR", "True")
|
||||
get_AE._right_output_analysis(
|
||||
2,
|
||||
get_options[3],
|
||||
get_options[0],
|
||||
"EmotionDetector",
|
||||
True,
|
||||
"SOME_VAR",
|
||||
50,
|
||||
50,
|
||||
50,
|
||||
"OTHER_VAR",
|
||||
"CIE 1976",
|
||||
)
|
||||
117
ammico/test/test_faces.py
Обычный файл
@ -0,0 +1,117 @@
|
||||
import ammico.faces as fc
|
||||
import json
|
||||
import pytest
|
||||
import os
|
||||
|
||||
|
||||
def test_init_EmotionDetector(monkeypatch):
|
||||
# standard input
|
||||
monkeypatch.setattr("builtins.input", lambda _: "yes")
|
||||
ed = fc.EmotionDetector({}, accept_disclosure="OTHER_VAR")
|
||||
assert ed.subdict["face"] == "No"
|
||||
assert ed.subdict["multiple_faces"] == "No"
|
||||
assert ed.subdict["wears_mask"] == ["No"]
|
||||
assert ed.emotion_threshold == 50
|
||||
assert ed.race_threshold == 50
|
||||
assert ed.gender_threshold == 50
|
||||
assert ed.emotion_categories["angry"] == "Negative"
|
||||
assert ed.emotion_categories["happy"] == "Positive"
|
||||
assert ed.emotion_categories["surprise"] == "Neutral"
|
||||
assert ed.accepted
|
||||
monkeypatch.delenv("OTHER_VAR", raising=False)
|
||||
# different thresholds
|
||||
ed = fc.EmotionDetector(
|
||||
{},
|
||||
emotion_threshold=80,
|
||||
race_threshold=30,
|
||||
gender_threshold=60,
|
||||
accept_disclosure="OTHER_VAR",
|
||||
)
|
||||
assert ed.emotion_threshold == 80
|
||||
assert ed.race_threshold == 30
|
||||
assert ed.gender_threshold == 60
|
||||
monkeypatch.delenv("OTHER_VAR", raising=False)
|
||||
# do not accept disclosure
|
||||
monkeypatch.setattr("builtins.input", lambda _: "no")
|
||||
ed = fc.EmotionDetector({}, accept_disclosure="OTHER_VAR")
|
||||
assert os.environ.get("OTHER_VAR") == "False"
|
||||
assert not ed.accepted
|
||||
monkeypatch.delenv("OTHER_VAR", raising=False)
|
||||
# now test the exceptions: thresholds
|
||||
monkeypatch.setattr("builtins.input", lambda _: "yes")
|
||||
with pytest.raises(ValueError):
|
||||
fc.EmotionDetector({}, emotion_threshold=150)
|
||||
with pytest.raises(ValueError):
|
||||
fc.EmotionDetector({}, emotion_threshold=-50)
|
||||
with pytest.raises(ValueError):
|
||||
fc.EmotionDetector({}, race_threshold=150)
|
||||
with pytest.raises(ValueError):
|
||||
fc.EmotionDetector({}, race_threshold=-50)
|
||||
with pytest.raises(ValueError):
|
||||
fc.EmotionDetector({}, gender_threshold=150)
|
||||
with pytest.raises(ValueError):
|
||||
fc.EmotionDetector({}, gender_threshold=-50)
|
||||
# test pre-set variables: disclosure
|
||||
monkeypatch.delattr("builtins.input", raising=False)
|
||||
monkeypatch.setenv("OTHER_VAR", "something")
|
||||
ed = fc.EmotionDetector({}, accept_disclosure="OTHER_VAR")
|
||||
assert not ed.accepted
|
||||
monkeypatch.setenv("OTHER_VAR", "False")
|
||||
ed = fc.EmotionDetector({}, accept_disclosure="OTHER_VAR")
|
||||
assert not ed.accepted
|
||||
monkeypatch.setenv("OTHER_VAR", "True")
|
||||
ed = fc.EmotionDetector({}, accept_disclosure="OTHER_VAR")
|
||||
assert ed.accepted
|
||||
|
||||
|
||||
def test_define_actions(monkeypatch):
|
||||
monkeypatch.setenv("OTHER_VAR", "True")
|
||||
ed = fc.EmotionDetector({}, accept_disclosure="OTHER_VAR")
|
||||
ed._define_actions({"wears_mask": True})
|
||||
assert ed.actions == ["age"]
|
||||
ed._define_actions({"wears_mask": False})
|
||||
assert ed.actions == ["age", "gender", "race", "emotion"]
|
||||
monkeypatch.setenv("OTHER_VAR", "False")
|
||||
ed = fc.EmotionDetector({}, accept_disclosure="OTHER_VAR")
|
||||
ed._define_actions({"wears_mask": True})
|
||||
assert ed.actions == []
|
||||
ed._define_actions({"wears_mask": False})
|
||||
assert ed.actions == ["emotion"]
|
||||
|
||||
|
||||
def test_ensure_deepface_models(monkeypatch):
|
||||
monkeypatch.setenv("OTHER_VAR", "True")
|
||||
ed = fc.EmotionDetector({}, accept_disclosure="OTHER_VAR")
|
||||
ed.actions = ["age", "gender", "race", "emotion"]
|
||||
ed._ensure_deepface_models()
|
||||
|
||||
|
||||
def test_analyse_faces(get_path, monkeypatch):
|
||||
mydict = {
|
||||
# one face, no mask
|
||||
"pexels-pixabay-415829": {"filename": get_path + "pexels-pixabay-415829.jpg"},
|
||||
# two faces, no mask
|
||||
"pexels-1000990-1954659": {"filename": get_path + "pexels-1000990-1954659.jpg"},
|
||||
# one face, mask
|
||||
"pexels-maksgelatin-4750169": {
|
||||
"filename": get_path + "pexels-maksgelatin-4750169.jpg"
|
||||
},
|
||||
}
|
||||
monkeypatch.setenv("OTHER_VAR", "True")
|
||||
for key in mydict.keys():
|
||||
mydict[key].update(
|
||||
fc.EmotionDetector(
|
||||
mydict[key], emotion_threshold=80, accept_disclosure="OTHER_VAR"
|
||||
).analyse_image()
|
||||
)
|
||||
|
||||
with open(get_path + "example_faces.json", "r") as file:
|
||||
out_dict = json.load(file)
|
||||
|
||||
for key in mydict.keys():
|
||||
# delete the filename key
|
||||
mydict[key].pop("filename", None)
|
||||
# do not test for age, as this is not a reliable metric
|
||||
mydict[key].pop("age", None)
|
||||
for subkey in mydict[key].keys():
|
||||
assert mydict[key][subkey] == out_dict[key][subkey]
|
||||
204
ammico/test/test_text.py
Обычный файл
@ -0,0 +1,204 @@
|
||||
import pytest
|
||||
import ammico.text as tt
|
||||
import spacy
|
||||
import json
|
||||
import sys
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def set_testdict(get_path):
|
||||
testdict = {
|
||||
"IMG_3755": {
|
||||
"filename": get_path + "IMG_3755.jpg",
|
||||
},
|
||||
"IMG_3756": {
|
||||
"filename": get_path + "IMG_3756.jpg",
|
||||
},
|
||||
"IMG_3757": {
|
||||
"filename": get_path + "IMG_3757.jpg",
|
||||
},
|
||||
}
|
||||
return testdict
|
||||
|
||||
|
||||
LANGUAGES = ["de", "en", "en"]
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def accepted(monkeypatch):
|
||||
monkeypatch.setenv("OTHER_VAR", "True")
|
||||
tt.TextDetector({}, accept_privacy="OTHER_VAR")
|
||||
return "OTHER_VAR"
|
||||
|
||||
|
||||
def test_privacy_statement(monkeypatch):
|
||||
# test pre-set variables: privacy
|
||||
monkeypatch.delattr("builtins.input", raising=False)
|
||||
monkeypatch.setenv("OTHER_VAR", "something")
|
||||
with pytest.raises(ValueError):
|
||||
tt.TextDetector({}, accept_privacy="OTHER_VAR")
|
||||
monkeypatch.setenv("OTHER_VAR", "False")
|
||||
with pytest.raises(ValueError):
|
||||
tt.TextDetector({}, accept_privacy="OTHER_VAR")
|
||||
with pytest.raises(ValueError):
|
||||
tt.TextDetector({}, accept_privacy="OTHER_VAR").get_text_from_image()
|
||||
with pytest.raises(ValueError):
|
||||
tt.TextDetector({}, accept_privacy="OTHER_VAR").translate_text()
|
||||
monkeypatch.setenv("OTHER_VAR", "True")
|
||||
pd = tt.TextDetector({}, accept_privacy="OTHER_VAR")
|
||||
assert pd.accepted
|
||||
|
||||
|
||||
def test_TextDetector(set_testdict, accepted):
|
||||
for item in set_testdict:
|
||||
test_obj = tt.TextDetector(set_testdict[item], accept_privacy=accepted)
|
||||
assert not test_obj.analyse_text
|
||||
assert not test_obj.skip_extraction
|
||||
assert test_obj.subdict["filename"] == set_testdict[item]["filename"]
|
||||
test_obj = tt.TextDetector(
|
||||
{}, analyse_text=True, skip_extraction=True, accept_privacy=accepted
|
||||
)
|
||||
assert test_obj.analyse_text
|
||||
assert test_obj.skip_extraction
|
||||
with pytest.raises(ValueError):
|
||||
tt.TextDetector({}, analyse_text=1.0, accept_privacy=accepted)
|
||||
with pytest.raises(ValueError):
|
||||
tt.TextDetector({}, skip_extraction=1.0, accept_privacy=accepted)
|
||||
|
||||
|
||||
def test_run_spacy(set_testdict, get_path, accepted):
|
||||
test_obj = tt.TextDetector(
|
||||
set_testdict["IMG_3755"], analyse_text=True, accept_privacy=accepted
|
||||
)
|
||||
ref_file = get_path + "text_IMG_3755.txt"
|
||||
with open(ref_file, "r") as file:
|
||||
reference_text = file.read()
|
||||
test_obj.subdict["text_english"] = reference_text
|
||||
test_obj._run_spacy()
|
||||
assert isinstance(test_obj.doc, spacy.tokens.doc.Doc)
|
||||
|
||||
|
||||
def test_check_add_space_after_full_stop(accepted):
|
||||
test_obj = tt.TextDetector({}, accept_privacy=accepted)
|
||||
test_obj.subdict["text"] = "I like cats. I like dogs."
|
||||
test_obj._check_add_space_after_full_stop()
|
||||
assert test_obj.subdict["text"] == "I like cats. I like dogs."
|
||||
test_obj.subdict["text"] = "I like cats."
|
||||
test_obj._check_add_space_after_full_stop()
|
||||
assert test_obj.subdict["text"] == "I like cats."
|
||||
test_obj.subdict["text"] = "www.icanhascheezburger.com"
|
||||
test_obj._check_add_space_after_full_stop()
|
||||
assert test_obj.subdict["text"] == "www. icanhascheezburger. com"
|
||||
|
||||
|
||||
def test_truncate_text(accepted):
|
||||
test_obj = tt.TextDetector({}, accept_privacy=accepted)
|
||||
test_obj.subdict["text"] = "I like cats and dogs."
|
||||
test_obj._truncate_text()
|
||||
assert test_obj.subdict["text"] == "I like cats and dogs."
|
||||
assert "text_truncated" not in test_obj.subdict
|
||||
test_obj.subdict["text"] = 20000 * "m"
|
||||
test_obj._truncate_text()
|
||||
assert test_obj.subdict["text_truncated"] == 5000 * "m"
|
||||
assert test_obj.subdict["text"] == 20000 * "m"
|
||||
|
||||
|
||||
@pytest.mark.gcv
|
||||
def test_analyse_image(set_testdict, set_environ, accepted):
|
||||
for item in set_testdict:
|
||||
test_obj = tt.TextDetector(set_testdict[item], accept_privacy=accepted)
|
||||
test_obj.analyse_image()
|
||||
test_obj = tt.TextDetector(
|
||||
set_testdict[item], analyse_text=True, accept_privacy=accepted
|
||||
)
|
||||
test_obj.analyse_image()
|
||||
testdict = {}
|
||||
testdict["text"] = 20000 * "m"
|
||||
test_obj = tt.TextDetector(
|
||||
testdict, skip_extraction=True, analyse_text=True, accept_privacy=accepted
|
||||
)
|
||||
test_obj.analyse_image()
|
||||
assert test_obj.subdict["text_truncated"] == 5000 * "m"
|
||||
assert test_obj.subdict["text"] == 20000 * "m"
|
||||
|
||||
|
||||
@pytest.mark.gcv
|
||||
def test_get_text_from_image(set_testdict, get_path, set_environ, accepted):
|
||||
for item in set_testdict:
|
||||
test_obj = tt.TextDetector(set_testdict[item], accept_privacy=accepted)
|
||||
test_obj.get_text_from_image()
|
||||
ref_file = get_path + "text_" + item + ".txt"
|
||||
with open(ref_file, "r", encoding="utf8") as file:
|
||||
reference_text = file.read().replace("\n", " ")
|
||||
assert test_obj.subdict["text"].replace("\n", " ") == reference_text
|
||||
|
||||
|
||||
def test_translate_text(set_testdict, get_path, accepted):
|
||||
for item, lang in zip(set_testdict, LANGUAGES):
|
||||
test_obj = tt.TextDetector(set_testdict[item], accept_privacy=accepted)
|
||||
ref_file = get_path + "text_" + item + ".txt"
|
||||
trans_file = get_path + "text_translated_" + item + ".txt"
|
||||
with open(ref_file, "r", encoding="utf8") as file:
|
||||
reference_text = file.read().replace("\n", " ")
|
||||
with open(trans_file, "r", encoding="utf8") as file:
|
||||
true_translated_text = file.read().replace("\n", " ")
|
||||
test_obj.subdict["text"] = reference_text
|
||||
test_obj.translate_text()
|
||||
assert test_obj.subdict["text_language"] == lang
|
||||
translated_text = test_obj.subdict["text_english"].lower().replace("\n", " ")
|
||||
for word in true_translated_text.lower():
|
||||
assert word in translated_text
|
||||
|
||||
|
||||
def test_remove_linebreaks(accepted):
|
||||
test_obj = tt.TextDetector({}, accept_privacy=accepted)
|
||||
test_obj.subdict["text"] = "This is \n a test."
|
||||
test_obj.subdict["text_english"] = "This is \n another\n test."
|
||||
test_obj.remove_linebreaks()
|
||||
assert test_obj.subdict["text"] == "This is a test."
|
||||
assert test_obj.subdict["text_english"] == "This is another test."
|
||||
|
||||
|
||||
def test_init_csv_option(get_path):
|
||||
test_obj = tt.TextAnalyzer(csv_path=get_path + "test.csv")
|
||||
assert test_obj.csv_path == get_path + "test.csv"
|
||||
assert test_obj.column_key == "text"
|
||||
assert test_obj.csv_encoding == "utf-8"
|
||||
test_obj = tt.TextAnalyzer(
|
||||
csv_path=get_path + "test.csv", column_key="mytext", csv_encoding="utf-16"
|
||||
)
|
||||
assert test_obj.column_key == "mytext"
|
||||
assert test_obj.csv_encoding == "utf-16"
|
||||
with pytest.raises(ValueError):
|
||||
tt.TextAnalyzer(csv_path=1.0)
|
||||
with pytest.raises(ValueError):
|
||||
tt.TextAnalyzer(csv_path="something")
|
||||
with pytest.raises(FileNotFoundError):
|
||||
tt.TextAnalyzer(csv_path=get_path + "test_no.csv")
|
||||
with pytest.raises(ValueError):
|
||||
tt.TextAnalyzer(csv_path=get_path + "test.csv", column_key=1.0)
|
||||
with pytest.raises(ValueError):
|
||||
tt.TextAnalyzer(csv_path=get_path + "test.csv", csv_encoding=1.0)
|
||||
|
||||
|
||||
@pytest.mark.skipif(sys.platform == "win32", reason="Encoding different on Window")
|
||||
def test_read_csv(get_path):
|
||||
test_obj = tt.TextAnalyzer(csv_path=get_path + "test.csv")
|
||||
test_obj.read_csv()
|
||||
with open(get_path + "test_read_csv_ref.json", "r") as file:
|
||||
ref_dict = json.load(file)
|
||||
# we are assuming the order did not get jungled up
|
||||
for (_, value_test), (_, value_ref) in zip(
|
||||
test_obj.mydict.items(), ref_dict.items()
|
||||
):
|
||||
assert value_test["text"] == value_ref["text"]
|
||||
# test with different encoding
|
||||
test_obj = tt.TextAnalyzer(
|
||||
csv_path=get_path + "test-utf16.csv", csv_encoding="utf-16"
|
||||
)
|
||||
test_obj.read_csv()
|
||||
# we are assuming the order did not get jungled up
|
||||
for (_, value_test), (_, value_ref) in zip(
|
||||
test_obj.mydict.items(), ref_dict.items()
|
||||
):
|
||||
assert value_test["text"] == value_ref["text"]
|
||||
152
ammico/test/test_utils.py
Обычный файл
@ -0,0 +1,152 @@
|
||||
import json
|
||||
import pandas as pd
|
||||
import ammico.utils as ut
|
||||
import pytest
|
||||
import os
|
||||
|
||||
|
||||
def test_find_files(get_path):
|
||||
with pytest.raises(FileNotFoundError):
|
||||
ut.find_files(path=".", pattern="*.png")
|
||||
|
||||
result_jpg = ut.find_files(path=get_path, pattern=".jpg", recursive=True, limit=10)
|
||||
assert 0 < len(result_jpg) <= 10
|
||||
|
||||
result_png = ut.find_files(path=get_path, pattern=".png", recursive=True, limit=10)
|
||||
assert 0 < len(result_png) <= 10
|
||||
|
||||
result_png_jpg = ut.find_files(
|
||||
path=get_path, pattern=["png", "jpg"], recursive=True, limit=10
|
||||
)
|
||||
assert 0 < len(result_png_jpg) <= 10
|
||||
|
||||
result_png_jpg = ut.find_files(
|
||||
path=get_path, pattern=["png", "jpg"], recursive=True, limit=4
|
||||
)
|
||||
assert 0 < len(result_png_jpg) <= 4
|
||||
|
||||
result_png_jpg = ut.find_files(
|
||||
path=get_path, pattern=["png", "jpg"], recursive=True, limit=[2, 4]
|
||||
)
|
||||
assert 0 < len(result_png_jpg) <= 2
|
||||
|
||||
one_dir_up_path = os.path.join(get_path, "..")
|
||||
with pytest.raises(FileNotFoundError):
|
||||
ut.find_files(
|
||||
path=one_dir_up_path, pattern=["png", "jpg"], recursive=False, limit=[2, 4]
|
||||
)
|
||||
|
||||
result_png_jpg = ut.find_files(
|
||||
path=one_dir_up_path, pattern=["png", "jpg"], recursive=True, limit=[2, 4]
|
||||
)
|
||||
assert 0 < len(result_png_jpg) <= 2
|
||||
|
||||
result_png_jpg = ut.find_files(
|
||||
path=get_path, pattern=["png", "jpg"], recursive=True, limit=None
|
||||
)
|
||||
assert 0 < len(result_png_jpg)
|
||||
result_png_jpg = ut.find_files(
|
||||
path=get_path, pattern=["png", "jpg"], recursive=True, limit=-1
|
||||
)
|
||||
assert 0 < len(result_png_jpg)
|
||||
|
||||
result_png_jpg_rdm1 = ut.find_files(
|
||||
path=get_path, pattern=["png", "jpg"], recursive=True, limit=2, random_seed=1
|
||||
)
|
||||
result_png_jpg_rdm2 = ut.find_files(
|
||||
path=get_path, pattern=["png", "jpg"], recursive=True, limit=2, random_seed=2
|
||||
)
|
||||
assert result_png_jpg_rdm1 != result_png_jpg_rdm2
|
||||
assert len(result_png_jpg_rdm1) == len(result_png_jpg_rdm2)
|
||||
|
||||
with pytest.raises(ValueError):
|
||||
ut.find_files(path=get_path, pattern=["png", "jpg"], recursive=True, limit=-2)
|
||||
with pytest.raises(ValueError):
|
||||
ut.find_files(
|
||||
path=get_path, pattern=["png", "jpg"], recursive=True, limit=[2, 4, 5]
|
||||
)
|
||||
with pytest.raises(ValueError):
|
||||
ut.find_files(path=get_path, pattern=["png", "jpg"], recursive=True, limit=[2])
|
||||
with pytest.raises(ValueError):
|
||||
ut.find_files(
|
||||
path=get_path, pattern=["png", "jpg"], recursive=True, limit="limit"
|
||||
)
|
||||
|
||||
|
||||
def test_initialize_dict(get_path):
|
||||
result = [
|
||||
"./test/data/image_faces.jpg",
|
||||
"./test/data/image_objects.jpg",
|
||||
]
|
||||
mydict = ut.initialize_dict(result)
|
||||
with open(get_path + "example_utils_init_dict.json", "r") as file:
|
||||
out_dict = json.load(file)
|
||||
assert mydict == out_dict
|
||||
|
||||
|
||||
def test_check_for_missing_keys():
|
||||
mydict = {
|
||||
"file1": {"faces": "Yes", "text_english": "Something"},
|
||||
"file2": {"faces": "No", "text_english": "Otherthing"},
|
||||
}
|
||||
# check that dict is not changed
|
||||
mydict2 = ut._check_for_missing_keys(mydict)
|
||||
assert mydict2 == mydict
|
||||
# check that dict is updated if key is missing
|
||||
mydict = {
|
||||
"file1": {"faces": "Yes", "text_english": "Something"},
|
||||
"file2": {"faces": "No"},
|
||||
}
|
||||
mydict2 = ut._check_for_missing_keys(mydict)
|
||||
assert mydict2["file2"] == {"faces": "No", "text_english": None}
|
||||
# check that dict is updated if more than one key is missing
|
||||
mydict = {"file1": {"faces": "Yes", "text_english": "Something"}, "file2": {}}
|
||||
mydict2 = ut._check_for_missing_keys(mydict)
|
||||
assert mydict2["file2"] == {"faces": None, "text_english": None}
|
||||
|
||||
|
||||
def test_append_data_to_dict(get_path):
|
||||
with open(get_path + "example_append_data_to_dict_in.json", "r") as file:
|
||||
mydict = json.load(file)
|
||||
outdict = ut.append_data_to_dict(mydict)
|
||||
print(outdict)
|
||||
with open(get_path + "example_append_data_to_dict_out.json", "r") as file:
|
||||
example_outdict = json.load(file)
|
||||
|
||||
assert outdict == example_outdict
|
||||
|
||||
|
||||
def test_dump_df(get_path):
|
||||
with open(get_path + "example_append_data_to_dict_out.json", "r") as file:
|
||||
outdict = json.load(file)
|
||||
df = ut.dump_df(outdict)
|
||||
out_df = pd.read_csv(get_path + "example_dump_df.csv", index_col=[0])
|
||||
pd.testing.assert_frame_equal(df, out_df)
|
||||
|
||||
|
||||
def test_get_dataframe(get_path):
|
||||
with open(get_path + "example_append_data_to_dict_in.json", "r") as file:
|
||||
mydict = json.load(file)
|
||||
out_df = pd.read_csv(get_path + "example_dump_df.csv", index_col=[0])
|
||||
df = ut.get_dataframe(mydict)
|
||||
df.to_csv("data_out.csv")
|
||||
pd.testing.assert_frame_equal(df, out_df)
|
||||
|
||||
|
||||
def test_is_interactive():
|
||||
assert ut.is_interactive
|
||||
|
||||
|
||||
def test_get_color_table():
|
||||
colors = ut.get_color_table()
|
||||
assert colors["Pink"] == {
|
||||
"ColorName": [
|
||||
"Pink",
|
||||
"LightPink",
|
||||
"HotPink",
|
||||
"DeepPink",
|
||||
"PaleVioletRed",
|
||||
"MediumVioletRed",
|
||||
],
|
||||
"HEX": ["#FFC0CB", "#FFB6C1", "#FF69B4", "#FF1493", "#DB7093", "#C71585"],
|
||||
}
|
||||
323
ammico/text.py
Обычный файл
@ -0,0 +1,323 @@
|
||||
from google.cloud import vision
|
||||
from google.auth.exceptions import DefaultCredentialsError
|
||||
from googletrans import Translator
|
||||
import spacy
|
||||
import io
|
||||
import os
|
||||
import re
|
||||
from ammico.utils import AnalysisMethod
|
||||
import grpc
|
||||
import pandas as pd
|
||||
|
||||
PRIVACY_STATEMENT = """The Text Detector uses Google Cloud Vision
|
||||
and Google Translate. Detailed information about how information
|
||||
is being processed is provided here:
|
||||
https://ssciwr.github.io/AMMICO/build/html/faq_link.html.
|
||||
Google’s privacy policy can be read here: https://policies.google.com/privacy.
|
||||
By continuing to use this Detector, you agree to send the data you want analyzed
|
||||
to the Google servers for extraction and translation."""
|
||||
|
||||
|
||||
def privacy_disclosure(accept_privacy: str = "PRIVACY_AMMICO"):
|
||||
"""
|
||||
Asks the user to accept the privacy statement.
|
||||
|
||||
Args:
|
||||
accept_privacy (str): The name of the disclosure variable (default: "PRIVACY_AMMICO").
|
||||
"""
|
||||
if not os.environ.get(accept_privacy):
|
||||
accepted = _ask_for_privacy_acceptance(accept_privacy)
|
||||
elif os.environ.get(accept_privacy) == "False":
|
||||
accepted = False
|
||||
elif os.environ.get(accept_privacy) == "True":
|
||||
accepted = True
|
||||
else:
|
||||
print(
|
||||
"Could not determine privacy disclosure - skipping \
|
||||
text detection and translation."
|
||||
)
|
||||
accepted = False
|
||||
return accepted
|
||||
|
||||
|
||||
def _ask_for_privacy_acceptance(accept_privacy: str = "PRIVACY_AMMICO"):
|
||||
"""
|
||||
Asks the user to accept the disclosure.
|
||||
"""
|
||||
print(PRIVACY_STATEMENT)
|
||||
answer = input("Do you accept the privacy disclosure? (yes/no): ")
|
||||
answer = answer.lower().strip()
|
||||
if answer == "yes":
|
||||
print("You have accepted the privacy disclosure.")
|
||||
print("""Text detection and translation will be performed.""")
|
||||
os.environ[accept_privacy] = "True"
|
||||
accepted = True
|
||||
elif answer == "no":
|
||||
print("You have not accepted the privacy disclosure.")
|
||||
print("No text detection and translation will be performed.")
|
||||
os.environ[accept_privacy] = "False"
|
||||
accepted = False
|
||||
else:
|
||||
print("Please answer with yes or no.")
|
||||
accepted = _ask_for_privacy_acceptance()
|
||||
return accepted
|
||||
|
||||
|
||||
class TextDetector(AnalysisMethod):
|
||||
def __init__(
|
||||
self,
|
||||
subdict: dict,
|
||||
analyse_text: bool = False,
|
||||
skip_extraction: bool = False,
|
||||
accept_privacy: str = "PRIVACY_AMMICO",
|
||||
) -> None:
|
||||
"""Init text detection class.
|
||||
|
||||
Args:
|
||||
subdict (dict): Dictionary containing file name/path, and possibly previous
|
||||
analysis results from other modules.
|
||||
analyse_text (bool, optional): Decide if extracted text will be further subject
|
||||
to analysis. Defaults to False.
|
||||
skip_extraction (bool, optional): Decide if text will be extracted from images or
|
||||
is already provided via a csv. Defaults to False.
|
||||
accept_privacy (str, optional): Environment variable to accept the privacy
|
||||
statement for the Google Cloud processing of the data. Defaults to
|
||||
"PRIVACY_AMMICO".
|
||||
"""
|
||||
super().__init__(subdict)
|
||||
# disable this for now
|
||||
# maybe it would be better to initialize the keys differently
|
||||
# the reason is that they are inconsistent depending on the selected
|
||||
# options, and also this may not be really necessary and rather restrictive
|
||||
# self.subdict.update(self.set_keys())
|
||||
self.accepted = privacy_disclosure(accept_privacy)
|
||||
if not self.accepted:
|
||||
raise ValueError(
|
||||
"Privacy disclosure not accepted - skipping text detection."
|
||||
)
|
||||
self.translator = Translator(raise_exception=True)
|
||||
if not isinstance(analyse_text, bool):
|
||||
raise ValueError("analyse_text needs to be set to true or false")
|
||||
self.analyse_text = analyse_text
|
||||
self.skip_extraction = skip_extraction
|
||||
if not isinstance(skip_extraction, bool):
|
||||
raise ValueError("skip_extraction needs to be set to true or false")
|
||||
if self.skip_extraction:
|
||||
print("Skipping text extraction from image.")
|
||||
print("Reading text directly from provided dictionary.")
|
||||
if self.analyse_text:
|
||||
self._initialize_spacy()
|
||||
|
||||
def set_keys(self) -> dict:
|
||||
"""Set the default keys for text analysis.
|
||||
|
||||
Returns:
|
||||
dict: The dictionary with default text keys.
|
||||
"""
|
||||
params = {"text": None, "text_language": None, "text_english": None}
|
||||
return params
|
||||
|
||||
def _initialize_spacy(self):
|
||||
"""Initialize the Spacy library for text analysis."""
|
||||
try:
|
||||
self.nlp = spacy.load("en_core_web_md")
|
||||
except Exception:
|
||||
spacy.cli.download("en_core_web_md")
|
||||
self.nlp = spacy.load("en_core_web_md")
|
||||
|
||||
def _check_add_space_after_full_stop(self):
|
||||
"""Add a space after a full stop. Required by googletrans."""
|
||||
# we have found text, now we check for full stops
|
||||
index_stop = [
|
||||
i.start()
|
||||
for i in re.finditer("\.", self.subdict["text"]) # noqa
|
||||
]
|
||||
if not index_stop: # no full stops found
|
||||
return
|
||||
# check if this includes the last string item
|
||||
end_of_list = False
|
||||
if len(self.subdict["text"]) <= (index_stop[-1] + 1):
|
||||
# the last found full stop is at the end of the string
|
||||
# but we can include all others
|
||||
if len(index_stop) == 1:
|
||||
end_of_list = True
|
||||
else:
|
||||
index_stop.pop()
|
||||
if end_of_list: # only one full stop at end of string
|
||||
return
|
||||
# if this is not the end of the list, check if there is a space after the full stop
|
||||
no_space = [i for i in index_stop if self.subdict["text"][i + 1] != " "]
|
||||
if not no_space: # all full stops have a space after them
|
||||
return
|
||||
# else, amend the text
|
||||
add_one = 1
|
||||
for i in no_space:
|
||||
self.subdict["text"] = (
|
||||
self.subdict["text"][: i + add_one]
|
||||
+ " "
|
||||
+ self.subdict["text"][i + add_one :]
|
||||
)
|
||||
add_one += 1
|
||||
|
||||
def _truncate_text(self, max_length: int = 5000) -> str:
|
||||
"""Truncate the text if it is too long for googletrans."""
|
||||
if self.subdict["text"] and len(self.subdict["text"]) > max_length:
|
||||
print("Text is too long - truncating to {} characters.".format(max_length))
|
||||
self.subdict["text_truncated"] = self.subdict["text"][:max_length]
|
||||
|
||||
def analyse_image(self) -> dict:
|
||||
"""Perform text extraction and analysis of the text.
|
||||
|
||||
Returns:
|
||||
dict: The updated dictionary with text analysis results.
|
||||
"""
|
||||
if not self.skip_extraction:
|
||||
self.get_text_from_image()
|
||||
# check that text was found
|
||||
if not self.subdict["text"]:
|
||||
print("No text found - skipping analysis.")
|
||||
else:
|
||||
# make sure all full stops are followed by whitespace
|
||||
# otherwise googletrans breaks
|
||||
self._check_add_space_after_full_stop()
|
||||
self._truncate_text()
|
||||
self.translate_text()
|
||||
self.remove_linebreaks()
|
||||
if self.analyse_text and self.subdict["text_english"]:
|
||||
self._run_spacy()
|
||||
return self.subdict
|
||||
|
||||
def get_text_from_image(self):
|
||||
"""Detect text on the image using Google Cloud Vision API."""
|
||||
if not self.accepted:
|
||||
raise ValueError(
|
||||
"Privacy disclosure not accepted - skipping text detection."
|
||||
)
|
||||
path = self.subdict["filename"]
|
||||
try:
|
||||
client = vision.ImageAnnotatorClient()
|
||||
except DefaultCredentialsError:
|
||||
raise DefaultCredentialsError(
|
||||
"Please provide credentials for google cloud vision API, see https://cloud.google.com/docs/authentication/application-default-credentials."
|
||||
)
|
||||
with io.open(path, "rb") as image_file:
|
||||
content = image_file.read()
|
||||
image = vision.Image(content=content)
|
||||
# check for usual connection errors and retry if necessary
|
||||
try:
|
||||
response = client.text_detection(image=image)
|
||||
except grpc.RpcError as exc:
|
||||
print("Cloud vision API connection failed")
|
||||
print("Skipping this image ..{}".format(path))
|
||||
print("Connection failed with code {}: {}".format(exc.code(), exc))
|
||||
# here check if text was found on image
|
||||
if response:
|
||||
texts = response.text_annotations[0].description
|
||||
self.subdict["text"] = texts
|
||||
else:
|
||||
print("No text found on image.")
|
||||
self.subdict["text"] = None
|
||||
if response.error.message:
|
||||
print("Google Cloud Vision Error")
|
||||
raise ValueError(
|
||||
"{}\nFor more info on error messages, check: "
|
||||
"https://cloud.google.com/apis/design/errors".format(
|
||||
response.error.message
|
||||
)
|
||||
)
|
||||
|
||||
def translate_text(self):
|
||||
"""Translate the detected text to English using the Translator object."""
|
||||
if not self.accepted:
|
||||
raise ValueError(
|
||||
"Privacy disclosure not accepted - skipping text translation."
|
||||
)
|
||||
text_to_translate = (
|
||||
self.subdict["text_truncated"]
|
||||
if "text_truncated" in self.subdict
|
||||
else self.subdict["text"]
|
||||
)
|
||||
try:
|
||||
translated = self.translator.translate(text_to_translate)
|
||||
except Exception:
|
||||
print("Could not translate the text with error {}.".format(Exception))
|
||||
translated = None
|
||||
print("Skipping translation for this text.")
|
||||
self.subdict["text_language"] = translated.src if translated else None
|
||||
self.subdict["text_english"] = translated.text if translated else None
|
||||
|
||||
def remove_linebreaks(self):
|
||||
"""Remove linebreaks from original and translated text."""
|
||||
if self.subdict["text"] and self.subdict["text_english"]:
|
||||
self.subdict["text"] = self.subdict["text"].replace("\n", " ")
|
||||
self.subdict["text_english"] = self.subdict["text_english"].replace(
|
||||
"\n", " "
|
||||
)
|
||||
|
||||
def _run_spacy(self):
|
||||
"""Generate Spacy doc object for further text analysis."""
|
||||
self.doc = self.nlp(self.subdict["text_english"])
|
||||
|
||||
|
||||
class TextAnalyzer:
|
||||
"""Used to get text from a csv and then run the TextDetector on it."""
|
||||
|
||||
def __init__(
|
||||
self, csv_path: str, column_key: str = None, csv_encoding: str = "utf-8"
|
||||
) -> None:
|
||||
"""Init the TextTranslator class.
|
||||
|
||||
Args:
|
||||
csv_path (str): Path to the CSV file containing the text entries.
|
||||
column_key (str): Key for the column containing the text entries.
|
||||
Defaults to None.
|
||||
csv_encoding (str): Encoding of the CSV file. Defaults to "utf-8".
|
||||
"""
|
||||
self.csv_path = csv_path
|
||||
self.column_key = column_key
|
||||
self.csv_encoding = csv_encoding
|
||||
self._check_valid_csv_path()
|
||||
self._check_file_exists()
|
||||
if not self.column_key:
|
||||
print("No column key provided - using 'text' as default.")
|
||||
self.column_key = "text"
|
||||
if not self.csv_encoding:
|
||||
print("No encoding provided - using 'utf-8' as default.")
|
||||
self.csv_encoding = "utf-8"
|
||||
if not isinstance(self.column_key, str):
|
||||
raise ValueError("The provided column key is not a string.")
|
||||
if not isinstance(self.csv_encoding, str):
|
||||
raise ValueError("The provided encoding is not a string.")
|
||||
|
||||
def _check_valid_csv_path(self):
|
||||
if not isinstance(self.csv_path, str):
|
||||
raise ValueError("The provided path to the CSV file is not a string.")
|
||||
if not self.csv_path.endswith(".csv"):
|
||||
raise ValueError("The provided file is not a CSV file.")
|
||||
|
||||
def _check_file_exists(self):
|
||||
try:
|
||||
with open(self.csv_path, "r") as file: # noqa
|
||||
pass
|
||||
except FileNotFoundError:
|
||||
raise FileNotFoundError("The provided CSV file does not exist.")
|
||||
|
||||
def read_csv(self) -> dict:
|
||||
"""Read the CSV file and return the dictionary with the text entries.
|
||||
|
||||
Returns:
|
||||
dict: The dictionary with the text entries.
|
||||
"""
|
||||
df = pd.read_csv(self.csv_path, encoding=self.csv_encoding)
|
||||
|
||||
if self.column_key not in df:
|
||||
raise ValueError(
|
||||
"The provided column key is not in the CSV file. Please check."
|
||||
)
|
||||
self.mylist = df[self.column_key].to_list()
|
||||
self.mydict = {}
|
||||
for i, text in enumerate(self.mylist):
|
||||
self.mydict[self.csv_path + "row-" + str(i)] = {
|
||||
"filename": self.csv_path,
|
||||
"text": text,
|
||||
}
|
||||
229
ammico/utils.py
Обычный файл
@ -0,0 +1,229 @@
|
||||
import glob
|
||||
import os
|
||||
from pandas import DataFrame, read_csv
|
||||
import pooch
|
||||
import importlib_resources
|
||||
import collections
|
||||
import random
|
||||
|
||||
|
||||
pkg = importlib_resources.files("ammico")
|
||||
|
||||
|
||||
def iterable(arg):
|
||||
return isinstance(arg, collections.abc.Iterable) and not isinstance(arg, str)
|
||||
|
||||
|
||||
class DownloadResource:
|
||||
"""A remote resource that needs on demand downloading.
|
||||
|
||||
We use this as a wrapper to the pooch library. The wrapper registers
|
||||
each data file and allows prefetching through the CLI entry point
|
||||
ammico_prefetch_models.
|
||||
"""
|
||||
|
||||
# We store a list of defined resouces in a class variable, allowing
|
||||
# us prefetching from a CLI e.g. to bundle into a Docker image
|
||||
resources = []
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
DownloadResource.resources.append(self)
|
||||
self.kwargs = kwargs
|
||||
|
||||
def get(self):
|
||||
return pooch.retrieve(**self.kwargs)
|
||||
|
||||
|
||||
def ammico_prefetch_models():
|
||||
"""Prefetch all the download resources"""
|
||||
for res in DownloadResource.resources:
|
||||
res.get()
|
||||
|
||||
|
||||
class AnalysisMethod:
|
||||
"""Base class to be inherited by all analysis methods."""
|
||||
|
||||
def __init__(self, subdict: dict) -> None:
|
||||
self.subdict = subdict
|
||||
# define keys that will be set by the analysis
|
||||
|
||||
def set_keys(self):
|
||||
raise NotImplementedError()
|
||||
|
||||
def analyse_image(self):
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
def _match_pattern(path, pattern, recursive):
|
||||
# helper function for find_files
|
||||
# find all matches for a single pattern.
|
||||
|
||||
if pattern.startswith("."):
|
||||
pattern = pattern[1:]
|
||||
if recursive:
|
||||
search_path = f"{path}/**/*.{pattern}"
|
||||
else:
|
||||
search_path = f"{path}/*.{pattern}"
|
||||
return list(glob.glob(search_path, recursive=recursive))
|
||||
|
||||
|
||||
def _limit_results(results, limit):
|
||||
# helper function for find_files
|
||||
# use -1 or None to return all images
|
||||
if limit == -1 or limit is None:
|
||||
limit = len(results)
|
||||
|
||||
# limit or batch the images
|
||||
if isinstance(limit, int):
|
||||
if limit < -1:
|
||||
raise ValueError("limit must be an integer greater than 0 or equal to -1")
|
||||
results = results[:limit]
|
||||
|
||||
elif iterable(limit):
|
||||
if len(limit) == 2:
|
||||
results = results[limit[0] : limit[1]]
|
||||
else:
|
||||
raise ValueError(
|
||||
f"limit must be an integer or a tuple of length 2, but is {limit}"
|
||||
)
|
||||
else:
|
||||
raise ValueError(
|
||||
f"limit must be an integer or a tuple of length 2, but is {limit}"
|
||||
)
|
||||
|
||||
return results
|
||||
|
||||
|
||||
def find_files(
|
||||
path: str = None,
|
||||
pattern=["png", "jpg", "jpeg", "gif", "webp", "avif", "tiff"],
|
||||
recursive: bool = True,
|
||||
limit=20,
|
||||
random_seed: int = None,
|
||||
) -> dict:
|
||||
"""Find image files on the file system.
|
||||
|
||||
Args:
|
||||
path (str, optional): The base directory where we are looking for the images. Defaults
|
||||
to None, which uses the ammico data directory if set or the current
|
||||
working directory otherwise.
|
||||
pattern (str|list, optional): The naming pattern that the filename should match.
|
||||
Use either '.ext' or just 'ext'
|
||||
Defaults to ["png", "jpg", "jpeg", "gif", "webp", "avif","tiff"]. Can be used to allow other patterns or to only include
|
||||
specific prefixes or suffixes.
|
||||
recursive (bool, optional): Whether to recurse into subdirectories. Default is set to True.
|
||||
limit (int/list, optional): The maximum number of images to be found.
|
||||
Provide a list or tuple of length 2 to batch the images.
|
||||
Defaults to 20. To return all images, set to None or -1.
|
||||
random_seed (int, optional): The random seed to use for shuffling the images.
|
||||
If None is provided the data will not be shuffeled. Defaults to None.
|
||||
Returns:
|
||||
dict: A nested dictionary with file ids and all filenames including the path.
|
||||
"""
|
||||
|
||||
if path is None:
|
||||
path = os.environ.get("AMMICO_DATA_HOME", ".")
|
||||
|
||||
if isinstance(pattern, str):
|
||||
pattern = [pattern]
|
||||
results = []
|
||||
for p in pattern:
|
||||
results.extend(_match_pattern(path, p, recursive=recursive))
|
||||
|
||||
if len(results) == 0:
|
||||
raise FileNotFoundError(f"No files found in {path} with pattern '{pattern}'")
|
||||
|
||||
if random_seed is not None:
|
||||
random.seed(random_seed)
|
||||
random.shuffle(results)
|
||||
|
||||
images = _limit_results(results, limit)
|
||||
|
||||
return initialize_dict(images)
|
||||
|
||||
|
||||
def initialize_dict(filelist: list) -> dict:
|
||||
"""Initialize the nested dictionary for all the found images.
|
||||
|
||||
Args:
|
||||
filelist (list): The list of files to be analyzed, including their paths.
|
||||
Returns:
|
||||
dict: The nested dictionary with all image ids and their paths."""
|
||||
mydict = {}
|
||||
for img_path in filelist:
|
||||
id_ = os.path.splitext(os.path.basename(img_path))[0]
|
||||
mydict[id_] = {"filename": img_path}
|
||||
return mydict
|
||||
|
||||
|
||||
def _check_for_missing_keys(mydict: dict) -> dict:
|
||||
"""Check the nested dictionary for any missing keys in the subdicts.
|
||||
|
||||
Args:
|
||||
mydict(dict): The nested dictionary with keys to check.
|
||||
Returns:
|
||||
dict: The dictionary with keys appended."""
|
||||
# check that we actually got a nested dict
|
||||
# also get all keys for all items
|
||||
# currently we go through the whole dictionary twice
|
||||
# however, compared to the rest of the code this is negligible
|
||||
keylist = []
|
||||
for key in mydict.keys():
|
||||
if not isinstance(mydict[key], dict):
|
||||
raise ValueError(
|
||||
"Please provide a nested dictionary - you provided {}".format(key)
|
||||
)
|
||||
keylist.append(list(mydict[key].keys()))
|
||||
# find the longest list of keys
|
||||
max_keys = max(keylist, key=len)
|
||||
# now generate missing keys
|
||||
for key in mydict.keys():
|
||||
for mkey in max_keys:
|
||||
if mkey not in mydict[key].keys():
|
||||
mydict[key][mkey] = None
|
||||
return mydict
|
||||
|
||||
|
||||
def append_data_to_dict(mydict: dict) -> dict:
|
||||
"""Append entries from nested dictionaries to keys in a global dict."""
|
||||
|
||||
# first initialize empty list for each key that is present
|
||||
outdict = {key: [] for key in list(mydict.values())[0].keys()}
|
||||
# now append the values to each key in a list
|
||||
for subdict in mydict.values():
|
||||
for key in subdict.keys():
|
||||
outdict[key].append(subdict[key])
|
||||
return outdict
|
||||
|
||||
|
||||
def dump_df(mydict: dict) -> DataFrame:
|
||||
"""Utility to dump the dictionary into a dataframe."""
|
||||
return DataFrame.from_dict(mydict)
|
||||
|
||||
|
||||
def get_dataframe(mydict: dict) -> DataFrame:
|
||||
_check_for_missing_keys(mydict)
|
||||
outdict = append_data_to_dict(mydict)
|
||||
return dump_df(outdict)
|
||||
|
||||
|
||||
def is_interactive():
|
||||
"""Check if we are running in an interactive environment."""
|
||||
import __main__ as main
|
||||
|
||||
return not hasattr(main, "__file__")
|
||||
|
||||
|
||||
def get_color_table():
|
||||
path_tables = pkg / "data" / "Color_tables.csv"
|
||||
df_colors = read_csv(
|
||||
path_tables,
|
||||
delimiter=";",
|
||||
dtype=str,
|
||||
encoding="UTF-8",
|
||||
header=[0, 1],
|
||||
)
|
||||
return {
|
||||
col_key: df_colors[col_key].dropna().to_dict("list")
|
||||
for col_key in df_colors.columns.levels[0]
|
||||
}
|
||||
Двоичные данные
data/ref/ref-00.png
{kind=link}
|
До Ширина: | Высота: | Размер: 6.1 KiB |
Двоичные данные
data/ref/ref-01.png
{kind=link}
|
До Ширина: | Высота: | Размер: 2.5 KiB |
Двоичные данные
data/ref/ref-02.png
{kind=link}
|
До Ширина: | Высота: | Размер: 4.5 KiB |
Двоичные данные
data/ref/ref-03.png
{kind=link}
|
До Ширина: | Высота: | Размер: 3.3 KiB |
Двоичные данные
data/ref/ref-04.png
{kind=link}
|
До Ширина: | Высота: | Размер: 4.1 KiB |
Двоичные данные
data/ref/ref-05.png
{kind=link}
|
До Ширина: | Высота: | Размер: 3.3 KiB |
Двоичные данные
data/ref/ref-06.png
{kind=link}
|
До Ширина: | Высота: | Размер: 5.2 KiB |
Двоичные данные
data/ref/ref-07.png
{kind=link}
|
До Ширина: | Высота: | Размер: 1.3 KiB |
Двоичные данные
data/ref/ref-08.png
{kind=link}
|
До Ширина: | Высота: | Размер: 14 KiB |
0
docs/.nojekyll
Обычный файл
20
docs/Makefile
Обычный файл
@ -0,0 +1,20 @@
|
||||
# Minimal makefile for Sphinx documentation
|
||||
#
|
||||
|
||||
# You can set these variables from the command line, and also
|
||||
# from the environment for the first two.
|
||||
SPHINXOPTS ?=
|
||||
SPHINXBUILD ?= sphinx-build
|
||||
SOURCEDIR = source
|
||||
BUILDDIR = build
|
||||
|
||||
# Put it first so that "make" without argument is like "make help".
|
||||
help:
|
||||
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||
|
||||
.PHONY: help Makefile
|
||||
|
||||
# Catch-all target: route all unknown targets to Sphinx using the new
|
||||
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
||||
%: Makefile
|
||||
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||
2
docs/index.html
Обычный файл
@ -0,0 +1,2 @@
|
||||
<meta http-equiv="refresh" content="0; url=./build/html/index.html" />
|
||||
|
||||
35
docs/make.bat
Обычный файл
@ -0,0 +1,35 @@
|
||||
@ECHO OFF
|
||||
|
||||
pushd %~dp0
|
||||
|
||||
REM Command file for Sphinx documentation
|
||||
|
||||
if "%SPHINXBUILD%" == "" (
|
||||
set SPHINXBUILD=sphinx-build
|
||||
)
|
||||
set SOURCEDIR=source
|
||||
set BUILDDIR=build
|
||||
|
||||
%SPHINXBUILD% >NUL 2>NUL
|
||||
if errorlevel 9009 (
|
||||
echo.
|
||||
echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
|
||||
echo.installed, then set the SPHINXBUILD environment variable to point
|
||||
echo.to the full path of the 'sphinx-build' executable. Alternatively you
|
||||
echo.may add the Sphinx directory to PATH.
|
||||
echo.
|
||||
echo.If you don't have Sphinx installed, grab it from
|
||||
echo.https://www.sphinx-doc.org/
|
||||
exit /b 1
|
||||
)
|
||||
|
||||
if "%1" == "" goto help
|
||||
|
||||
%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
||||
goto end
|
||||
|
||||
:help
|
||||
%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
||||
|
||||
:end
|
||||
popd
|
||||
Двоичные данные
docs/source/_static/emotion_detector.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 83 KiB |
Двоичные данные
docs/source/_static/summary_detector.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 505 KiB |
Двоичные данные
docs/source/_static/text_detector.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 70 KiB |
63
docs/source/ammico.rst
Обычный файл
@ -0,0 +1,63 @@
|
||||
text module
|
||||
-----------
|
||||
|
||||
.. automodule:: text
|
||||
:members:
|
||||
:undoc-members:
|
||||
:show-inheritance:
|
||||
|
||||
summary module
|
||||
--------------
|
||||
|
||||
.. automodule:: summary
|
||||
:members:
|
||||
:undoc-members:
|
||||
:show-inheritance:
|
||||
|
||||
multimodal search module
|
||||
------------------------
|
||||
|
||||
.. automodule:: multimodal_search
|
||||
:members:
|
||||
:undoc-members:
|
||||
:show-inheritance:
|
||||
|
||||
faces module
|
||||
------------
|
||||
|
||||
.. automodule:: faces
|
||||
:members:
|
||||
:undoc-members:
|
||||
:show-inheritance:
|
||||
|
||||
color_analysis module
|
||||
---------------------
|
||||
|
||||
.. automodule:: colors
|
||||
:members:
|
||||
:undoc-members:
|
||||
:show-inheritance:
|
||||
|
||||
cropposts module
|
||||
----------------
|
||||
|
||||
.. automodule:: cropposts
|
||||
:members:
|
||||
:undoc-members:
|
||||
:show-inheritance:
|
||||
|
||||
utils module
|
||||
------------
|
||||
|
||||
.. automodule:: utils
|
||||
:members:
|
||||
:undoc-members:
|
||||
:show-inheritance:
|
||||
|
||||
display module
|
||||
--------------
|
||||
|
||||
.. automodule:: display
|
||||
:members:
|
||||
:undoc-members:
|
||||
:show-inheritance:
|
||||
45
docs/source/conf.py
Обычный файл
@ -0,0 +1,45 @@
|
||||
# Configuration file for the Sphinx documentation builder.
|
||||
#
|
||||
# For the full list of built-in configuration values, see the documentation:
|
||||
# https://www.sphinx-doc.org/en/master/usage/configuration.html
|
||||
|
||||
import os
|
||||
import sys
|
||||
|
||||
sys.path.insert(0, os.path.abspath("../../ammico/"))
|
||||
|
||||
|
||||
# -- Project information -----------------------------------------------------
|
||||
# https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information
|
||||
|
||||
project = "AMMICO"
|
||||
copyright = "2022, Scientific Software Center, Heidelberg University"
|
||||
author = "Scientific Software Center, Heidelberg University"
|
||||
release = "0.2.2"
|
||||
|
||||
# -- General configuration ---------------------------------------------------
|
||||
# https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration
|
||||
|
||||
extensions = ["sphinx.ext.autodoc", "sphinx.ext.napoleon", "myst_parser", "nbsphinx"]
|
||||
nbsphinx_allow_errors = True
|
||||
nbsphinx_execute = "never"
|
||||
napoleon_custom_sections = [("Returns", "params_style")]
|
||||
myst_heading_anchors = 3
|
||||
|
||||
html_context = {
|
||||
"display_github": True, # Integrate GitHub
|
||||
"github_user": "ssciwr", # Username
|
||||
"github_repo": "AMMICO", # Repo name
|
||||
"github_version": "main", # Version
|
||||
"conf_py_path": "/docs/source/", # Path in the checkout to the docs root
|
||||
}
|
||||
|
||||
templates_path = ["_templates"]
|
||||
exclude_patterns = ["_build", "Thumbs.db", ".DS_Store"]
|
||||
|
||||
|
||||
# -- Options for HTML output -------------------------------------------------
|
||||
# https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output
|
||||
|
||||
html_theme = "sphinx_rtd_theme"
|
||||
html_static_path = ["_static"]
|
||||
2
docs/source/create_API_key_link.md
Обычный файл
@ -0,0 +1,2 @@
|
||||
```{include} set_up_credentials.md
|
||||
```
|
||||
2
docs/source/faq_link.md
Обычный файл
@ -0,0 +1,2 @@
|
||||
```{include} ../../FAQ.md
|
||||
```
|
||||
Двоичные данные
docs/source/img0.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 130 KiB |
Двоичные данные
docs/source/img1.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 145 KiB |
Двоичные данные
docs/source/img10.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 134 KiB |
Двоичные данные
docs/source/img11.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 69 KiB |
Двоичные данные
docs/source/img12.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 50 KiB |
Двоичные данные
docs/source/img13.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 48 KiB |
Двоичные данные
docs/source/img14.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 73 KiB |
Двоичные данные
docs/source/img15.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 81 KiB |
Двоичные данные
docs/source/img16.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 42 KiB |
Двоичные данные
docs/source/img17.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 113 KiB |
Двоичные данные
docs/source/img18.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 61 KiB |
Двоичные данные
docs/source/img19.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 56 KiB |
Двоичные данные
docs/source/img2.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 51 KiB |
Двоичные данные
docs/source/img3.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 54 KiB |
Двоичные данные
docs/source/img4.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 124 KiB |
Двоичные данные
docs/source/img5.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 133 KiB |
Двоичные данные
docs/source/img6.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 80 KiB |
Двоичные данные
docs/source/img7.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 107 KiB |
Двоичные данные
docs/source/img8.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 131 KiB |
Двоичные данные
docs/source/img9.png
Обычный файл
{kind=link}
|
После Ширина: | Высота: | Размер: 80 KiB |
26
docs/source/index.rst
Обычный файл
@ -0,0 +1,26 @@
|
||||
.. ammico documentation master file, created by
|
||||
sphinx-quickstart on Mon Dec 19 13:39:22 2022.
|
||||
You can adapt this file completely to your liking, but it should at least
|
||||
contain the root `toctree` directive.
|
||||
|
||||
Welcome to AMMICO's documentation!
|
||||
==================================
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 2
|
||||
:caption: Contents:
|
||||
|
||||
readme_link
|
||||
faq_link
|
||||
create_API_key_link
|
||||
notebooks/DemoNotebook_ammico
|
||||
notebooks/Example cropposts
|
||||
modules
|
||||
license_link
|
||||
|
||||
Indices and tables
|
||||
==================
|
||||
|
||||
* :ref:`genindex`
|
||||
* :ref:`modindex`
|
||||
* :ref:`search`
|
||||
4
docs/source/license_link.md
Обычный файл
@ -0,0 +1,4 @@
|
||||
# License
|
||||
|
||||
```{include} ../../LICENSE
|
||||
```
|
||||
7
docs/source/modules.rst
Обычный файл
@ -0,0 +1,7 @@
|
||||
AMMICO package modules
|
||||
======================
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 4
|
||||
|
||||
ammico
|
||||
1538
docs/source/notebooks/DemoNotebook_ammico.ipynb
Обычный файл
2
docs/source/readme_link.md
Обычный файл
@ -0,0 +1,2 @@
|
||||
```{include} ../../README.md
|
||||
```
|
||||
44
docs/source/set_up_credentials.md
Обычный файл
@ -0,0 +1,44 @@
|
||||
# Instructions how to generate and enable a google Cloud Vision API key
|
||||
|
||||
1. Go to [google-cloud-vision](https://cloud.google.com/vision) and click on "Console". Sign into your google account / create a new google account if prompted. This will bring you to the following page, where you click on "project" in the top of the screen.
|
||||

|
||||
2. Select "project" from the top left drop-down menu.
|
||||

|
||||
3. Click on "NEW PROJECT" on the left of the pop-up window.
|
||||

|
||||
4. Enter a project name and click on "CREATE".
|
||||

|
||||
5. Now you should be back on the dashboard. In the top right, click on the three vertical dots.
|
||||

|
||||
6. In the drop-down menu, select "Project settings".
|
||||

|
||||
7. In the menu on the left, click on "Service Accounts".
|
||||

|
||||
8. Click on "+ CREATE SERVICE ACCOUNT".
|
||||

|
||||
9. Select a service account ID (you can pick this as any name you wish). Click on "DONE".
|
||||

|
||||
10. Now your service account should show up in the list of service accounts.
|
||||

|
||||
11. Click on the three vertical dots to the right of your service account name and select "Manage keys".
|
||||

|
||||
12. Click on "Create new key".
|
||||

|
||||
13. In the pop-up window, select "JSON" and click "CREATE".
|
||||

|
||||
14. The private key is directly downloaded to your computer. It should be in your downloads folder.
|
||||

|
||||
15. The JSON key file will look something like this (any private information has been blanked out in the screenshot).
|
||||

|
||||
16. Now go back to your browser window. Click on "Google Cloud" in the top left corner.
|
||||

|
||||
17. Now select "APIs & Services".
|
||||

|
||||
18. From the selection of APIs, select "Cloud Vision API" or search for it and then select.
|
||||

|
||||
19. Click on "ENABLE".
|
||||

|
||||
20. Google Cloud Vision API is now enabled for your key.
|
||||

|
||||
21. Place the JSON key in a selected folder on your computer and reference this key in your Jupyter Notebook / Python console when running ammico. Or, upload it to your google Drive to use it on google Colaboratory.
|
||||
22. Make sure that [billing is enabled](https://support.google.com/googleapi/answer/6158867?hl=en) for your google account. You can get the first three month for free; after that, you will be charged if processing more than 1000 images / month (currently $1.50 per 1000 images, see [here](https://cloud.google.com/vision/pricing/)).
|
||||